数组中的 k-diff 数对
难度:
标签:
题目描述
给你一个整数数组 nums 和一个整数 k,请你在数组中找出 不同的 k-diff 数对,并返回不同的 k-diff 数对 的数目。
k-diff 数对定义为一个整数对 (nums[i], nums[j]) ,并满足下述全部条件:
0 <= i, j < nums.lengthi != j|nums[i] - nums[j]| == k
注意,|val| 表示 val 的绝对值。
示例 1:
输入:nums = [3, 1, 4, 1, 5], k = 2 输出:2 解释:数组中有两个 2-diff 数对, (1, 3) 和 (3, 5)。 尽管数组中有两个 1 ,但我们只应返回不同的数对的数量。
示例 2:
输入:nums = [1, 2, 3, 4, 5], k = 1 输出:4 解释:数组中有四个 1-diff 数对, (1, 2), (2, 3), (3, 4) 和 (4, 5) 。
示例 3:
输入:nums = [1, 3, 1, 5, 4], k = 0 输出:1 解释:数组中只有一个 0-diff 数对,(1, 1) 。
提示:
1 <= nums.length <= 104-107 <= nums[i] <= 1070 <= k <= 107
代码结果
运行时间: 24 ms, 内存: 17.7 MB
/*
* 题目思路:
* 1. 使用Java Stream API进行数据处理。
* 2. 创建一个哈希集合来存储数组中的数字。
* 3. 使用stream遍历数组,对于每个数字检查它的加上k或减去k的值是否在哈希集合中。
* 4. 将符合条件的数对加入到已找到的数对集合中。
* 5. 最后返回已找到的数对集合的大小。
*/
import java.util.HashSet;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class KDiffPairsStream {
public int findPairs(int[] nums, int k) {
if (k < 0) return 0;
Set<Integer> numSet = new HashSet<>();
Set<Integer> foundPairs = IntStream.of(nums)
.filter(num -> {
boolean found = numSet.contains(num - k) || numSet.contains(num + k);
numSet.add(num);
return found;
})
.mapToObj(num -> num - k)
.collect(Collectors.toSet());
return foundPairs.size();
}
}
解释
方法:
该题解的思路是首先判断k是否为0,如果k为0,则直接统计nums中出现次数大于1的元素个数并返回。如果k不为0,则先将nums去重,然后遍历nums中的每个元素x,判断x+k是否也在nums中,如果在则将count加1,最后返回count的值。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
为什么在k为0的情况下,选择使用Counter来统计元素出现次数而不是其他方法?
▷🦆
在处理k不为0的情况时,将nums转换为set来去重,这一做法是否会影响最终结果中数对的唯一性判断?
▷🦆
题解中提到的`x+k是否也在nums中`的判断逻辑,是否考虑了k为负数的情况,这会如何影响算法的输出?
▷🦆
算法中使用`lambda`函数和`map`来创建t列表,这种方法与直接使用循环有何优缺点?
▷相关问题
二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:
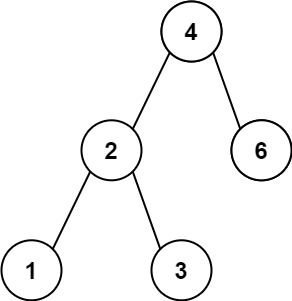
输入:root = [4,2,6,1,3] 输出:1
示例 2:
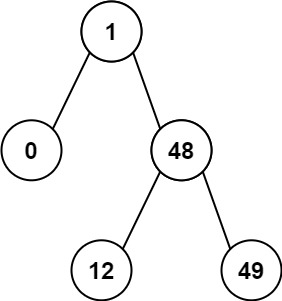
输入:root = [1,0,48,null,null,12,49] 输出:1
提示:
- 树中节点的数目范围是
[2, 104] 0 <= Node.val <= 105
注意:本题与 783 https://leetcode-cn.com/problems/minimum-distance-between-bst-nodes/ 相同