二叉搜索树中的中序后继
难度:
标签:
题目描述
代码结果
运行时间: 40 ms, 内存: 19.5 MB
/*
* 思路:
* 使用Java Stream API来进行中序遍历并找到目标节点的后继。
* 中序遍历结果存储在列表中,通过遍历列表找到目标节点的后一个节点。
*/
import java.util.*;
import java.util.stream.*;
public class Solution {
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
List<TreeNode> nodes = new ArrayList<>();
inorderTraversal(root, nodes);
for (int i = 0; i < nodes.size(); i++) {
if (nodes.get(i).val == p.val) {
return (i + 1 < nodes.size()) ? nodes.get(i + 1) : null;
}
}
return null;
}
private void inorderTraversal(TreeNode root, List<TreeNode> nodes) {
if (root == null) return;
inorderTraversal(root.left, nodes);
nodes.add(root);
inorderTraversal(root.right, nodes);
}
}
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}解释
方法:
该题解的思路是利用二叉搜索树的性质,中序遍历的后继节点有以下两种情况:
1. 如果给定节点 p 有右子树,则其中序后继为右子树中的最左节点。
2. 如果给定节点 p 没有右子树,则从根节点开始遍历,记录最后一个值小于 p 的节点,即为 p 的中序后继。
时间复杂度:
O(h),其中 h 为二叉搜索树的高度,平均情况下为 O(log(n))
空间复杂度:
O(1)
代码细节讲解
🦆
在题解中提到,如果给定节点 p 有右子树,则其中序后继为右子树中的最左节点。请问这是基于哪些二叉搜索树的特性得出的结论?
▷🦆
题解中提到,当 p 没有右子树时,需要从根节点开始遍历寻找最后一个值小于 p 的节点作为中序后继。为什么选择最后一个值小于 p 的节点作为后继?
▷🦆
题解的示例代码在处理没有右子树的情况时,设置了一个 nodeStay 变量来记录最后一个值小于 p 的节点。如果二叉树中存在多个节点的值等于 p 的值,这种处理方式是否仍然适用?
▷🦆
在题解的代码中,一旦发现 p 节点的值等于根节点的值且没有右子树,就直接返回 None。这种处理是否意味着根节点永远不会有中序后继?这是否总是正确的?
▷相关问题
二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3] 输出:[1,3,2]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
二叉搜索树迭代器
实现一个二叉搜索树迭代器类
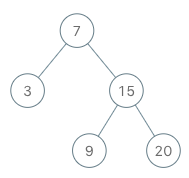
BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
BSTIterator(TreeNode root)初始化BSTIterator类的一个对象。BST 的根节点root会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。boolean hasNext()如果向指针右侧遍历存在数字,则返回true;否则返回false。int next()将指针向右移动,然后返回指针处的数字。
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
示例:
输入 ["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] 输出 [null, 3, 7, true, 9, true, 15, true, 20, false] 解释 BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); bSTIterator.next(); // 返回 3 bSTIterator.next(); // 返回 7 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 9 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 15 bSTIterator.hasNext(); // 返回 True bSTIterator.next(); // 返回 20 bSTIterator.hasNext(); // 返回 False
提示:
- 树中节点的数目在范围
[1, 105]内 0 <= Node.val <= 106- 最多调用
105次hasNext和next操作
进阶:
- 你可以设计一个满足下述条件的解决方案吗?
next()和hasNext()操作均摊时间复杂度为O(1),并使用O(h)内存。其中h是树的高度。