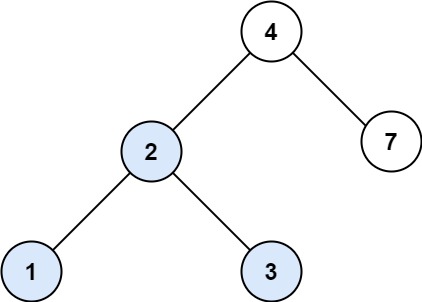
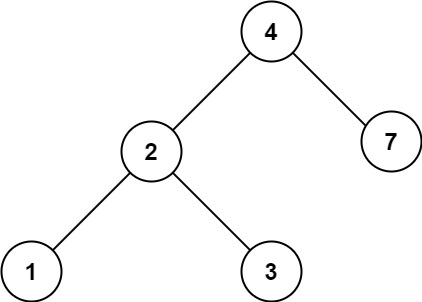
最接近的二叉搜索树值
难度:
标签:
题目描述
代码结果
运行时间: 23 ms, 内存: 18.0 MB
/*
* Problem: Closest Binary Search Tree Value
* Approach using Java Streams:
* 1. Convert the BST to a list using an in-order traversal.
* 2. Use Java Streams to find the closest value to the target.
*/
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class Solution {
public int closestValue(TreeNode root, double target) {
// In-order traversal to convert BST to a sorted list
List<Integer> values = new ArrayList<>();
inOrderTraversal(root, values);
// Find the closest value using Streams
return values.stream()
.min((a, b) -> Double.compare(Math.abs(a - target), Math.abs(b - target)))
.orElseThrow(() -> new IllegalArgumentException("Tree is empty"));
}
private void inOrderTraversal(TreeNode node, List<Integer> values) {
if (node != null) {
inOrderTraversal(node.left, values);
values.add(node.val);
inOrderTraversal(node.right, values);
}
}
}解释
方法:
该题解的思路是使用递归的方式对二叉搜索树进行遍历。首先定义一个内部函数calDiff,用于计算当前节点值与目标值之间的差值的绝对值,并将节点值和差值作为元组存储在nodeVal列表中。然后根据目标值与当前节点值的大小关系,选择递归遍历左子树或右子树。最后对nodeVal列表按照差值和节点值进行排序,返回差值最小的节点值。
时间复杂度:
O(nlogn)
空间复杂度:
O(n)
代码细节讲解
🦆
在你的递归函数`calDiff`中,当遇到`root`为`None`时,函数返回`None`。这种处理对最终结果有什么影响?
▷🦆
为何选择在每个递归调用结束后对`nodeVal`列表进行排序而不是在插入时就维护一个有序列表?
▷🦆
在排序操作中,使用了元组的第二个元素(差值)作为主要的排序关键字,如果存在多个节点值与目标值差值相同,选择最小的节点值作为返回值的原则是否总是适用?
▷🦆
你的解法中遍历了整个二叉搜索树,是否有更优的方法只遍历到必要的部分就停止?
▷相关问题
完全二叉树的节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例 1:

输入:root = [1,2,3,4,5,6] 输出:6
示例 2:
输入:root = [] 输出:0
示例 3:
输入:root = [1] 输出:1
提示:
- 树中节点的数目范围是
[0, 5 * 104] 0 <= Node.val <= 5 * 104- 题目数据保证输入的树是 完全二叉树
进阶:遍历树来统计节点是一种时间复杂度为 O(n) 的简单解决方案。你可以设计一个更快的算法吗?