课程表
难度:
标签:
题目描述
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]] 输出:true 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]] 输出:false 解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
代码结果
运行时间: 23 ms, 内存: 17.1 MB
// 思路:同样使用Kahn's Algorithm,但使用Java Stream来处理集合操作。
import java.util.*;
import java.util.stream.*;
public class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
int[] indegree = new int[numCourses];
Map<Integer, List<Integer>> graph = new HashMap<>();
for (int i = 0; i < numCourses; i++) {
graph.put(i, new ArrayList<>());
}
for (int[] prereq : prerequisites) {
graph.get(prereq[1]).add(prereq[0]);
indegree[prereq[0]]++;
}
Queue<Integer> queue = IntStream.range(0, numCourses)
.filter(i -> indegree[i] == 0)
.boxed()
.collect(Collectors.toCollection(LinkedList::new));
int count = 0;
while (!queue.isEmpty()) {
int course = queue.poll();
count++;
for (int next : graph.get(course)) {
if (--indegree[next] == 0) {
queue.offer(next);
}
}
}
return count == numCourses;
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
课程表 II
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]] 输出:[0,2,1,3] 解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。 因此,一个正确的课程顺序是[0,1,2,3]。另一个正确的排序是[0,2,1,3]。
示例 3:
输入:numCourses = 1, prerequisites = [] 输出:[0]
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- 所有
[ai, bi]互不相同
最小高度树
树是一个无向图,其中任何两个顶点只通过一条路径连接。 换句话说,任何一个没有简单环路的连通图都是一棵树。
给你一棵包含 n 个节点的树,标记为 0 到 n - 1 。给定数字 n 和一个有 n - 1 条无向边的 edges 列表(每一个边都是一对标签),其中 edges[i] = [ai, bi] 表示树中节点 ai 和 bi 之间存在一条无向边。
可选择树中任何一个节点作为根。当选择节点 x 作为根节点时,设结果树的高度为 h 。在所有可能的树中,具有最小高度的树(即,min(h))被称为 最小高度树 。
请你找到所有的 最小高度树 并按 任意顺序 返回它们的根节点标签列表。
树的 高度 是指根节点和叶子节点之间最长向下路径上边的数量。
示例 1:
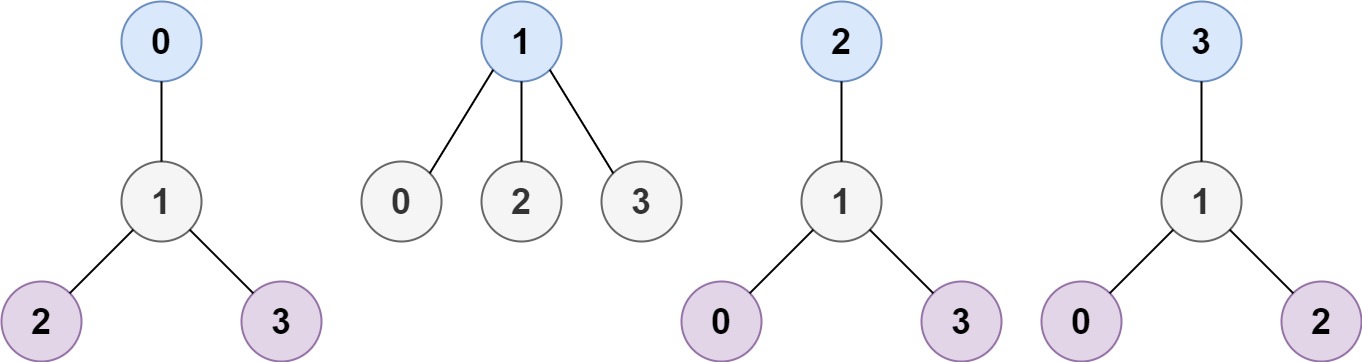
输入:n = 4, edges = [[1,0],[1,2],[1,3]] 输出:[1] 解释:如图所示,当根是标签为 1 的节点时,树的高度是 1 ,这是唯一的最小高度树。
示例 2:
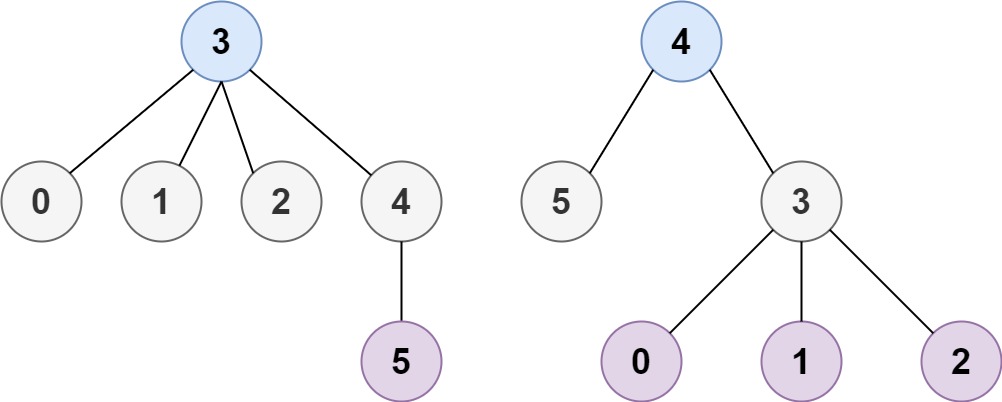
输入:n = 6, edges = [[3,0],[3,1],[3,2],[3,4],[5,4]] 输出:[3,4]
提示:
1 <= n <= 2 * 104edges.length == n - 10 <= ai, bi < nai != bi- 所有
(ai, bi)互不相同 - 给定的输入 保证 是一棵树,并且 不会有重复的边
课程表 III
这里有 n 门不同的在线课程,按从 1 到 n 编号。给你一个数组 courses ,其中 courses[i] = [durationi, lastDayi] 表示第 i 门课将会 持续 上 durationi 天课,并且必须在不晚于 lastDayi 的时候完成。
你的学期从第 1 天开始。且不能同时修读两门及两门以上的课程。
返回你最多可以修读的课程数目。
示例 1:
输入:courses = [[100, 200], [200, 1300], [1000, 1250], [2000, 3200]] 输出:3 解释: 这里一共有 4 门课程,但是你最多可以修 3 门: 首先,修第 1 门课,耗费 100 天,在第 100 天完成,在第 101 天开始下门课。 第二,修第 3 门课,耗费 1000 天,在第 1100 天完成,在第 1101 天开始下门课程。 第三,修第 2 门课,耗时 200 天,在第 1300 天完成。 第 4 门课现在不能修,因为将会在第 3300 天完成它,这已经超出了关闭日期。
示例 2:
输入:courses = [[1,2]] 输出:1
示例 3:
输入:courses = [[3,2],[4,3]] 输出:0
提示:
1 <= courses.length <= 1041 <= durationi, lastDayi <= 104