统计完全连通分量的数量
难度:
标签:
题目描述
You are given an integer n. There is an undirected graph with n vertices, numbered from 0 to n - 1. You are given a 2D integer array edges where edges[i] = [ai, bi] denotes that there exists an undirected edge connecting vertices ai and bi.
Return the number of complete connected components of the graph.
A connected component is a subgraph of a graph in which there exists a path between any two vertices, and no vertex of the subgraph shares an edge with a vertex outside of the subgraph.
A connected component is said to be complete if there exists an edge between every pair of its vertices.
Example 1:
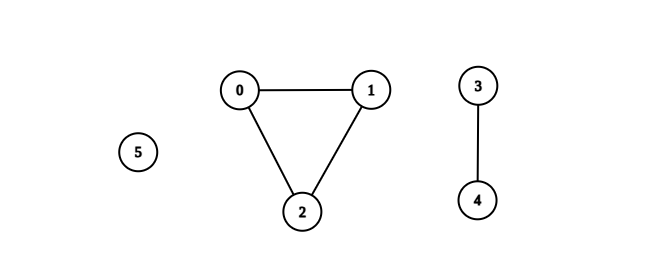
Input: n = 6, edges = [[0,1],[0,2],[1,2],[3,4]] Output: 3 Explanation: From the picture above, one can see that all of the components of this graph are complete.
Example 2:
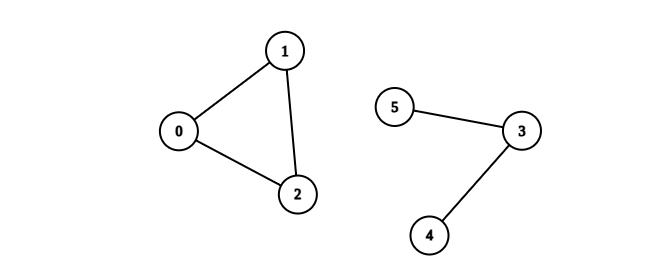
Input: n = 6, edges = [[0,1],[0,2],[1,2],[3,4],[3,5]] Output: 1 Explanation: The component containing vertices 0, 1, and 2 is complete since there is an edge between every pair of two vertices. On the other hand, the component containing vertices 3, 4, and 5 is not complete since there is no edge between vertices 4 and 5. Thus, the number of complete components in this graph is 1.
Constraints:
1 <= n <= 500 <= edges.length <= n * (n - 1) / 2edges[i].length == 20 <= ai, bi <= n - 1ai != bi- There are no repeated edges.
代码结果
运行时间: 74 ms, 内存: 16.5 MB
/*
* 思路:
* 1. 使用并查集(Union-Find)来找到所有连通分量。
* 2. 使用Java Stream来简化代码和数据处理。
* 3. 对每个连通分量,检查是否为完全连通分量。
*/
import java.util.*;
import java.util.stream.*;
public class Solution {
public int countCompleteComponents(int n, int[][] edges) {
int[] parent = IntStream.range(0, n).toArray();
int find(int x) {
return parent[x] == x ? x : (parent[x] = find(parent[x]));
}
void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) parent[rootY] = rootX;
}
Arrays.stream(edges).forEach(edge -> union(edge[0], edge[1]));
Map<Integer, Long> nodeCount = IntStream.range(0, n).boxed()
.collect(Collectors.groupingBy(this::find, Collectors.counting()));
Map<Integer, Long> edgeCount = Arrays.stream(edges).mapToInt(edge -> find(edge[0]))
.boxed().collect(Collectors.groupingBy(i -> i, Collectors.counting()));
return (int) nodeCount.entrySet().stream().filter(e ->
edgeCount.getOrDefault(e.getKey(), 0L) == e.getValue() * (e.getValue() - 1) / 2).count();
}
}解释
方法:
此题解采用的是广度优先搜索(BFS)来遍历图中的每个顶点,并同时记录每个连通分量中的顶点数(vertex_num)和边数的两倍(edge_num)。首先,构建了图的邻接表表示。然后,对于每个未访问的顶点,使用BFS来遍历其所在的连通分量,记录下顶点数和边数的两倍。在BFS过程中,每次从队列中取出一个顶点,增加顶点数,增加的边数为该顶点连接的边数(注意这里边数会被计算两次,即每条边的两个顶点各计一次)。最后,检查该连通分量是否为完全连通分量,即顶点数(vertex_num)和边数(edge_num)之间的关系是否符合完全图的性质(完全图的边数为顶点数 * (顶点数 - 1) / 2,因为边数edge_num统计了两次,因此直接比较vertex_num * (vertex_num - 1)和edge_num是否相等)。如果相等,说明是完全连通分量,答案加一。
时间复杂度:
O(V + E)
空间复杂度:
O(V + E)
代码细节讲解
🦆
在算法中,为什么需要将边的数量乘以二来计算?
▷🦆
当检查完全连通分量时,为何将顶点数(vertex_num)乘以(vertex_num - 1)与边数(edge_num)比较即可判断?
▷🦆
如果在图中存在自环或多重边,此算法是否需要调整?如果需要,应如何调整?
▷🦆
为什么在广度优先搜索(BFS)过程中,一旦访问一个顶点就立即将其加入到已访问集合中,而不是在出队时添加?
▷