二叉树展开为链表
难度:
标签:
题目描述
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:
输入:root = [1,2,5,3,4,null,6] 输出:[1,null,2,null,3,null,4,null,5,null,6]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [0] 输出:[0]
提示:
- 树中结点数在范围
[0, 2000]内 -100 <= Node.val <= 100
进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
代码结果
运行时间: 36 ms, 内存: 15 MB
/*
题目思路:
1. 使用递归的方式先序遍历二叉树,将节点存入列表。
2. 使用Java Stream将列表中的节点连接起来形成单链表。
*/
import java.util.*;
import java.util.stream.*;
class Solution {
public void flatten(TreeNode root) {
if (root == null) return;
List<TreeNode> nodes = new ArrayList<>();
preorderTraversal(root, nodes);
TreeNode curr = root;
for (TreeNode node : nodes) {
curr.left = null;
curr.right = node;
curr = node;
}
}
private void preorderTraversal(TreeNode node, List<TreeNode> nodes) {
if (node == null) return;
nodes.add(node);
preorderTraversal(node.left, nodes);
preorderTraversal(node.right, nodes);
}
}解释
方法:
该题解采用后序遍历的方式来展开二叉树为链表。具体思路如下:
1. 首先递归处理左子树,将左子树展开为链表。
2. 然后递归处理右子树,将右子树展开为链表。
3. 将原本的左子树作为根节点的右子树,原本的右子树拼接到当前右子树的末端。
4. 将根节点的左子树置为空。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
为什么在展开二叉树为链表的过程中选择使用后序遍历而不是先序或中序遍历?
▷🦆
在连接原左子树到根节点右侧后,如何确保整个链表保持先序遍历的顺序?
▷🦆
在将左子树置空之前,直接将左子树接到右子树的末端有没有可能会对原树结构造成破坏或数据丢失?
▷🦆
如果二叉树非常大,递归深度过大可能导致栈溢出。有没有非递归的方法可以实现同样的功能?
▷相关问题
扁平化多级双向链表
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
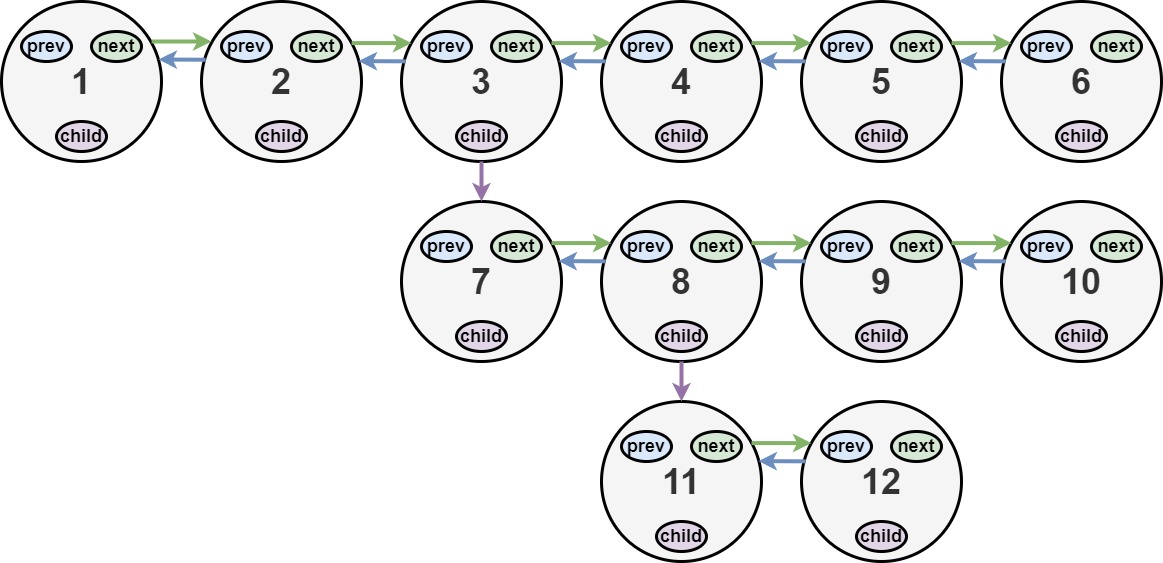
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] 输出:[1,2,3,7,8,11,12,9,10,4,5,6] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图:
示例 2:

输入:head = [1,2,null,3] 输出:[1,3,2] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图: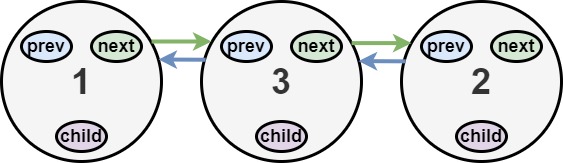
示例 3:
输入:head = [] 输出:[] 说明:输入中可能存在空列表。
提示:
- 节点数目不超过
1000 1 <= Node.val <= 105
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null] [null,null,7,8,9,10,null] [null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]