出现次数最多的子树元素和
难度:
标签:
题目描述
给你一个二叉树的根结点 root ,请返回出现次数最多的子树元素和。如果有多个元素出现的次数相同,返回所有出现次数最多的子树元素和(不限顺序)。
一个结点的 「子树元素和」 定义为以该结点为根的二叉树上所有结点的元素之和(包括结点本身)。
示例 1:

输入: root = [5,2,-3] 输出: [2,-3,4]
示例 2:

输入: root = [5,2,-5] 输出: [2]
提示:
- 节点数在
[1, 104]范围内 -105 <= Node.val <= 105
代码结果
运行时间: 56 ms, 内存: 19.2 MB
/*
* 题目思路:
* 1. 使用后序遍历计算每个节点的子树和,使用Stream API对结果进行处理。
* 2. 通过计算每个子树和的出现频率,找出出现次数最多的子树和。
* 3. 使用Collectors.groupingBy和Collectors.counting来实现统计。
*/
import java.util.*;
import java.util.stream.*;
class TreeNode {
int val;
TreeNode left, right;
TreeNode(int x) { val = x; }
}
public class Solution {
public int[] findFrequentTreeSum(TreeNode root) {
Map<Integer, Long> sumCount = new HashMap<>();
calculateSubtreeSum(root, sumCount);
long maxCount = sumCount.values().stream().max(Long::compare).orElse(0L);
return sumCount.entrySet().stream()
.filter(entry -> entry.getValue() == maxCount)
.map(Map.Entry::getKey)
.mapToInt(i -> i)
.toArray();
}
private int calculateSubtreeSum(TreeNode node, Map<Integer, Long> sumCount) {
if (node == null) return 0;
int leftSum = calculateSubtreeSum(node.left, sumCount);
int rightSum = calculateSubtreeSum(node.right, sumCount);
int totalSum = node.val + leftSum + rightSum;
sumCount.put(totalSum, sumCount.getOrDefault(totalSum, 0L) + 1);
return totalSum;
}
}解释
方法:
该题解采用后序遍历的方式递归计算每个子树的元素和,将所有子树元素和保存到一个列表中。然后使用 Counter 统计列表中每个元素和出现的次数,找出出现次数最多的元素和,并返回所有出现次数最多的元素和组成的列表。
时间复杂度:
O(nlogn)
空间复杂度:
O(n)
代码细节讲解
🦆
如何确保在计算子树元素和时,所有子树的元素都能被正确计算并累加?
▷🦆
在使用Counter统计元素出现次数后,为什么可以假设最常见的元素和一定在列表的第一个位置?
▷🦆
为什么在找到最大出现次数之后,题解选择使用一个循环而不是继续使用Counter的方法来找出所有最频繁的子树元素和?
▷相关问题
另一棵树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:
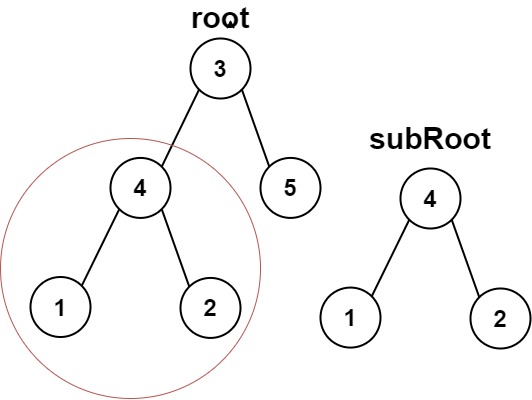
输入:root = [3,4,5,1,2], subRoot = [4,1,2] 输出:true
示例 2:
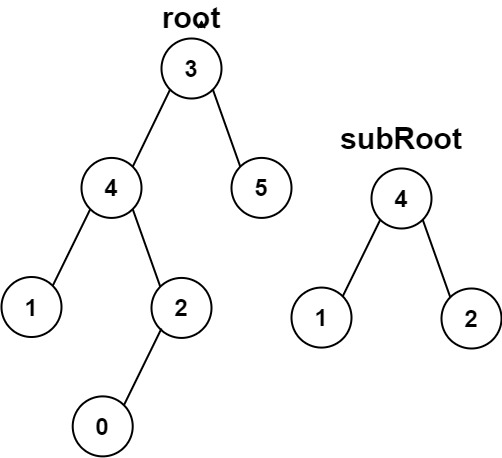
输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2] 输出:false
提示:
root树上的节点数量范围是[1, 2000]subRoot树上的节点数量范围是[1, 1000]-104 <= root.val <= 104-104 <= subRoot.val <= 104