寻找重复的子树
难度:
标签:
题目描述
给你一棵二叉树的根节点 root ,返回所有 重复的子树 。
对于同一类的重复子树,你只需要返回其中任意 一棵 的根结点即可。
如果两棵树具有 相同的结构 和 相同的结点值 ,则认为二者是 重复 的。
示例 1:

输入:root = [1,2,3,4,null,2,4,null,null,4] 输出:[[2,4],[4]]
示例 2:

输入:root = [2,1,1] 输出:[[1]]
示例 3:

输入:root = [2,2,2,3,null,3,null] 输出:[[2,3],[3]]
提示:
- 树中的结点数在
[1, 5000]范围内。 -200 <= Node.val <= 200
代码结果
运行时间: 32 ms, 内存: 17.9 MB
/*
* 题目思路:
* 同样地,我们需要找到二叉树中的重复子树。我们使用Java Stream API来实现序列化子树并检测重复。
* 使用递归和Collector将子树的序列化表示聚合到一个列表中,然后利用Collectors.groupingBy来分组计算相同子树的出现次数。
* 最后筛选出重复的子树。
*/
import java.util.*;
import java.util.stream.*;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public class Solution {
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
return findDuplicates(root).values().stream()
.filter(list -> list.size() > 1)
.map(list -> list.get(0))
.collect(Collectors.toList());
}
private Map<String, List<TreeNode>> findDuplicates(TreeNode node) {
if (node == null) return new HashMap<>();
Map<String, List<TreeNode>> leftMap = findDuplicates(node.left);
Map<String, List<TreeNode>> rightMap = findDuplicates(node.right);
String serial = node.val + "," + leftMap.keySet().stream().findFirst().orElse("#") + "," + rightMap.keySet().stream().findFirst().orElse("#");
Map<String, List<TreeNode>> currentMap = new HashMap<>();
currentMap.put(serial, new ArrayList<>(Arrays.asList(node)));
leftMap.forEach((key, value) -> currentMap.merge(key, value, (l1, l2) -> { l1.addAll(l2); return l1; }));
rightMap.forEach((key, value) -> currentMap.merge(key, value, (l1, l2) -> { l1.addAll(l2); return l1; }));
return currentMap;
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
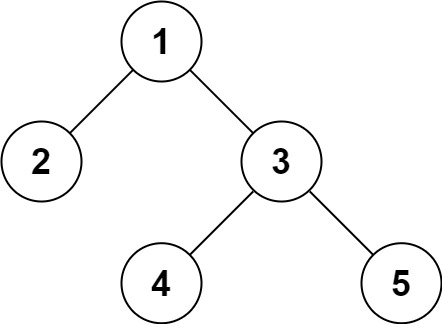
输入:root = [1,2,3,null,null,4,5] 输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:
输入:root = [1,2] 输出:[1,2]
提示:
- 树中结点数在范围
[0, 104]内 -1000 <= Node.val <= 1000
序列化和反序列化二叉搜索树
序列化是将数据结构或对象转换为一系列位的过程,以便它可以存储在文件或内存缓冲区中,或通过网络连接链路传输,以便稍后在同一个或另一个计算机环境中重建。
设计一个算法来序列化和反序列化 二叉搜索树 。 对序列化/反序列化算法的工作方式没有限制。 您只需确保二叉搜索树可以序列化为字符串,并且可以将该字符串反序列化为最初的二叉搜索树。
编码的字符串应尽可能紧凑。
示例 1:
输入:root = [2,1,3] 输出:[2,1,3]
示例 2:
输入:root = [] 输出:[]
提示:
- 树中节点数范围是
[0, 104] 0 <= Node.val <= 104- 题目数据 保证 输入的树是一棵二叉搜索树。
根据二叉树创建字符串
给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
空节点使用一对空括号对 "()" 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
示例 1:
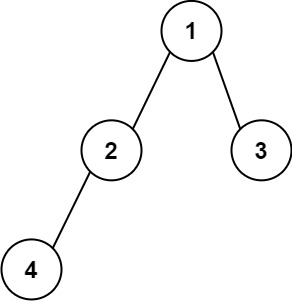
输入:root = [1,2,3,4] 输出:"1(2(4))(3)" 解释:初步转化后得到 "1(2(4)())(3()())" ,但省略所有不必要的空括号对后,字符串应该是"1(2(4))(3)" 。
示例 2:
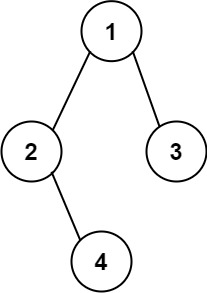
输入:root = [1,2,3,null,4] 输出:"1(2()(4))(3)" 解释:和第一个示例类似,但是无法省略第一个空括号对,否则会破坏输入与输出一一映射的关系。
提示:
- 树中节点的数目范围是
[1, 104] -1000 <= Node.val <= 1000