按权重随机选择
难度:
标签:
题目描述
代码结果
运行时间: 136 ms, 内存: 21.0 MB
/*
思路:
1. 使用 Stream API 进行前缀和数组的构建。
2. 使用 Random 类生成随机数,并用 Stream API 进行二分查找。
*/
import java.util.*;
import java.util.stream.IntStream;
class Solution {
private int[] prefixSums;
private int totalSum;
private Random rand;
public Solution(int[] w) {
prefixSums = IntStream.range(0, w.length)
.map(i -> IntStream.rangeClosed(0, i).map(j -> w[j]).sum())
.toArray();
totalSum = Arrays.stream(w).sum();
rand = new Random();
}
public int pickIndex() {
int target = rand.nextInt(totalSum);
return IntStream.range(0, prefixSums.length)
.filter(i -> prefixSums[i] > target)
.findFirst()
.orElse(-1);
}
}解释
方法:
此题解使用前缀和数组和二分查找算法来实现按权重随机选择的功能。首先,在初始化函数中,计算输入权重数组的前缀和,并存储总权重。在pickIndex函数中,随机生成一个介于1到总权重之间的整数,然后使用二分查找在前缀和数组中找到这个随机数应该插入的位置,该位置即为所选的下标。
时间复杂度:
O(log n)
空间复杂度:
O(n)
代码细节讲解
🦆
在实现中使用`accumulate(w)`计算前缀和时,如果输入数组`w`非常大,这种方式是否会引起性能瓶颈?
▷🦆
为什么在`pickIndex`函数中生成的随机数范围是从1到总权重`self.total`,而不是从0开始?
▷🦆
在使用`bisect_left`进行二分查找时,如果随机数正好等于前缀和数组中的某个值,这将如何影响结果?是否总是返回该值的最左侧下标?
▷🦆
考虑到前缀和数组是单调递增的,使用二分查找寻找下标的效率如何?与其他可能的查找方法相比,它的优势在哪里?
▷相关问题
随机数索引
给你一个可能含有 重复元素 的整数数组 nums ,请你随机输出给定的目标数字 target 的索引。你可以假设给定的数字一定存在于数组中。
实现 Solution 类:
Solution(int[] nums)用数组nums初始化对象。int pick(int target)从nums中选出一个满足nums[i] == target的随机索引i。如果存在多个有效的索引,则每个索引的返回概率应当相等。
示例:
输入 ["Solution", "pick", "pick", "pick"] [[[1, 2, 3, 3, 3]], [3], [1], [3]] 输出 [null, 4, 0, 2] 解释 Solution solution = new Solution([1, 2, 3, 3, 3]); solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。 solution.pick(1); // 返回 0 。因为只有 nums[0] 等于 1 。 solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。
提示:
1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 1target是nums中的一个整数- 最多调用
pick函数104次
黑名单中的随机数
给定一个整数 n 和一个 无重复 黑名单整数数组 blacklist 。设计一种算法,从 [0, n - 1] 范围内的任意整数中选取一个 未加入 黑名单 blacklist 的整数。任何在上述范围内且不在黑名单 blacklist 中的整数都应该有 同等的可能性 被返回。
优化你的算法,使它最小化调用语言 内置 随机函数的次数。
实现 Solution 类:
Solution(int n, int[] blacklist)初始化整数n和被加入黑名单blacklist的整数int pick()返回一个范围为[0, n - 1]且不在黑名单blacklist中的随机整数
示例 1:
输入
["Solution", "pick", "pick", "pick", "pick", "pick", "pick", "pick"]
[[7, [2, 3, 5]], [], [], [], [], [], [], []]
输出
[null, 0, 4, 1, 6, 1, 0, 4]
解释
Solution solution = new Solution(7, [2, 3, 5]);
solution.pick(); // 返回0,任何[0,1,4,6]的整数都可以。注意,对于每一个pick的调用,
// 0、1、4和6的返回概率必须相等(即概率为1/4)。
solution.pick(); // 返回 4
solution.pick(); // 返回 1
solution.pick(); // 返回 6
solution.pick(); // 返回 1
solution.pick(); // 返回 0
solution.pick(); // 返回 4
提示:
1 <= n <= 1090 <= blacklist.length <= min(105, n - 1)0 <= blacklist[i] < nblacklist中所有值都 不同-
pick最多被调用2 * 104次
非重叠矩形中的随机点
给定一个由非重叠的轴对齐矩形的数组 rects ,其中 rects[i] = [ai, bi, xi, yi] 表示 (ai, bi) 是第 i 个矩形的左下角点,(xi, yi) 是第 i 个矩形的右上角点。设计一个算法来随机挑选一个被某一矩形覆盖的整数点。矩形周长上的点也算做是被矩形覆盖。所有满足要求的点必须等概率被返回。
在给定的矩形覆盖的空间内的任何整数点都有可能被返回。
请注意 ,整数点是具有整数坐标的点。
实现 Solution 类:
Solution(int[][] rects)用给定的矩形数组rects初始化对象。int[] pick()返回一个随机的整数点[u, v]在给定的矩形所覆盖的空间内。
示例 1:
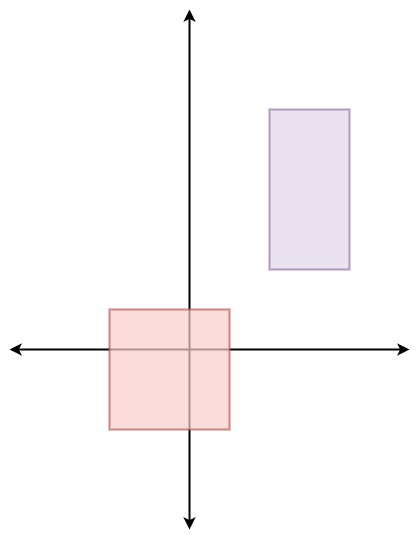
输入: ["Solution", "pick", "pick", "pick", "pick", "pick"] [[[[-2, -2, 1, 1], [2, 2, 4, 6]]], [], [], [], [], []] 输出: [null, [1, -2], [1, -1], [-1, -2], [-2, -2], [0, 0]] 解释: Solution solution = new Solution([[-2, -2, 1, 1], [2, 2, 4, 6]]); solution.pick(); // 返回 [1, -2] solution.pick(); // 返回 [1, -1] solution.pick(); // 返回 [-1, -2] solution.pick(); // 返回 [-2, -2] solution.pick(); // 返回 [0, 0]
提示:
1 <= rects.length <= 100rects[i].length == 4-109 <= ai < xi <= 109-109 <= bi < yi <= 109xi - ai <= 2000yi - bi <= 2000- 所有的矩形不重叠。
pick最多被调用104次。