N 叉树的前序遍历
难度:
标签:
题目描述
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:

输入:root = [1,null,3,2,4,null,5,6] 输出:[1,3,5,6,2,4]
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[1,2,3,6,7,11,14,4,8,12,5,9,13,10]
提示:
- 节点总数在范围
[0, 104]内 0 <= Node.val <= 104- n 叉树的高度小于或等于
1000
进阶:递归法很简单,你可以使用迭代法完成此题吗?
代码结果
运行时间: 28 ms, 内存: 17.6 MB
/*
题目思路:
1. n叉树的前序遍历是先访问根节点,然后依次访问每个子节点。
2. 使用Java Stream流操作可以简化代码。
3. 对于每个节点,先访问该节点的值,然后使用流操作递归访问子节点。
*/
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
// 定义n叉树节点
class Node {
public int val;
public List<Node> children;
public Node() {}
public Node(int val) {
this.val = val;
}
public Node(int val, List<Node> children) {
this.val = val;
this.children = children;
}
}
public class Solution {
public List<Integer> preorder(Node root) {
if (root == null) return new ArrayList<>();
return Stream.concat(
Stream.of(root.val),
root.children.stream().flatMap(child -> preorder(child).stream())
).collect(Collectors.toList());
}
}解释
方法:
这道题使用了递归的深度优先搜索(DFS)来完成N叉树的前序遍历。首先初始化结果列表res,如果根节点为空则直接返回空列表。然后定义辅助函数dfs,传入当前节点,如果当前节点为空则直接返回。将当前节点的值加入结果列表,然后对当前节点的所有子节点递归调用dfs。最后在主函数中调用dfs,并返回结果列表res。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
在递归函数`dfs`中,如果当前节点为空直接返回的情况会在哪种情况下发生,考虑到已经在主函数中检查了根节点是否为空?
▷🦆
您在递归函数`dfs`中遍历子节点的顺序是否影响了前序遍历的结果?如果是,如何确保结果符合前序遍历的顺序?
▷🦆
对于非递归的解决方案,如何使用栈来实现N叉树的前序遍历,并与递归方法在效率上进行比较?
▷🦆
递归深度和N叉树的形状有什么关系?能否举例说明在不同N叉树形状下递归深度的变化?
▷相关问题
二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:

输入:root = [1,null,2,3] 输出:[1,2,3]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:

输入:root = [1,2] 输出:[1,2]
示例 5:

输入:root = [1,null,2] 输出:[1,2]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶:递归算法很简单,你可以通过迭代算法完成吗?
N 叉树的层序遍历
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:
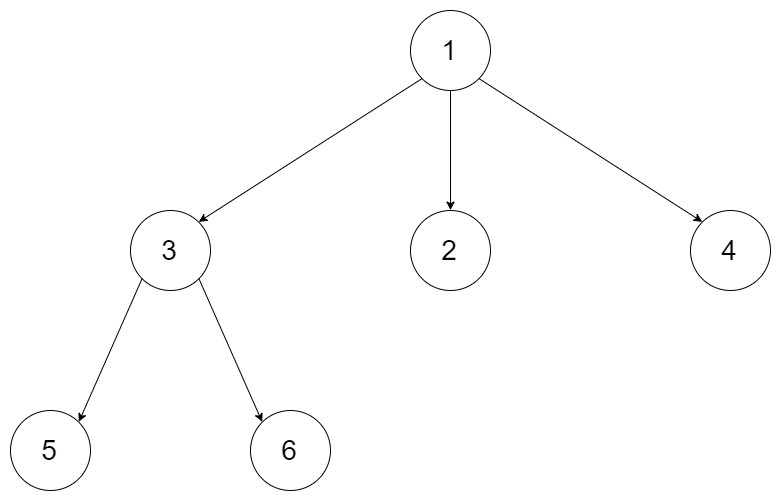
输入:root = [1,null,3,2,4,null,5,6] 输出:[[1],[3,2,4],[5,6]]
示例 2:
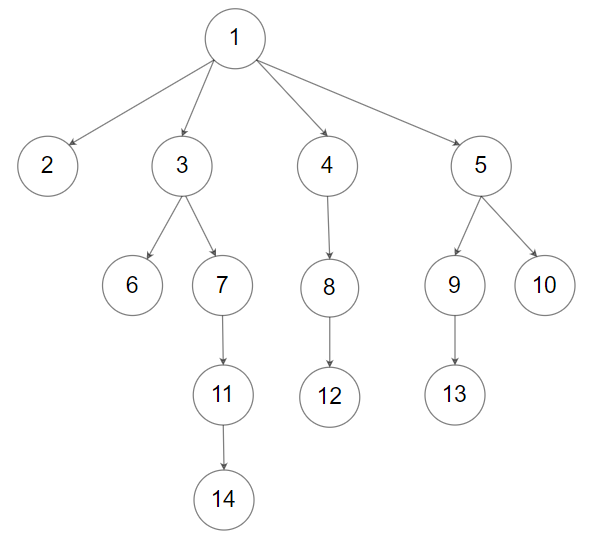
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
N 叉树的后序遍历
给定一个 n 叉树的根节点 root ,返回 其节点值的 后序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:
输入:root = [1,null,3,2,4,null,5,6] 输出:[5,6,3,2,4,1]
示例 2:
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[2,6,14,11,7,3,12,8,4,13,9,10,5,1]
提示:
- 节点总数在范围
[0, 104]内 0 <= Node.val <= 104- n 叉树的高度小于或等于
1000
进阶:递归法很简单,你可以使用迭代法完成此题吗?