字符串的编码与解码
难度:
标签:
题目描述
代码结果
运行时间: 47 ms, 内存: 16.2 MB
/*
* Problem 271: Encode and Decode Strings (Java Stream Version)
*
* Approach:
* 1. For encoding, we prepend each string with its length followed by a delimiter using Java Streams.
* 2. For decoding, we extract the length from the encoded string, and then extract the corresponding substring using Stream.
*/
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CodecStream {
// Encodes a list of strings to a single string.
public String encode(List<String> strs) {
return strs.stream()
.map(s -> s.length() + "#" + s)
.collect(Collectors.joining());
}
// Decodes a single string to a list of strings.
public List<String> decode(String s) {
List<String> decoded = new ArrayList<>();
int i = 0;
while (i < s.length()) {
int delimiterPos = s.indexOf('#', i);
int length = Integer.parseInt(s.substring(i, delimiterPos));
i = delimiterPos + 1 + length;
decoded.add(s.substring(delimiterPos + 1, i));
}
return decoded;
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
外观数列
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
countAndSay(1) = "1"countAndSay(n)是对countAndSay(n-1)的描述,然后转换成另一个数字字符串。
前五项如下:
1. 1 2. 11 3. 21 4. 1211 5. 111221 第一项是数字 1 描述前一项,这个数是1即 “ 一 个 1 ”,记作"11"描述前一项,这个数是11即 “ 二 个 1 ” ,记作"21"描述前一项,这个数是21即 “ 一 个 2 + 一 个 1 ” ,记作 "1211"描述前一项,这个数是1211即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 "111221"
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
例如,数字字符串 "3322251" 的描述如下图:

示例 1:
输入:n = 1 输出:"1" 解释:这是一个基本样例。
示例 2:
输入:n = 4 输出:"1211" 解释: countAndSay(1) = "1" countAndSay(2) = 读 "1" = 一 个 1 = "11" countAndSay(3) = 读 "11" = 二 个 1 = "21" countAndSay(4) = 读 "21" = 一 个 2 + 一 个 1 = "12" + "11" = "1211"
提示:
1 <= n <= 30
二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
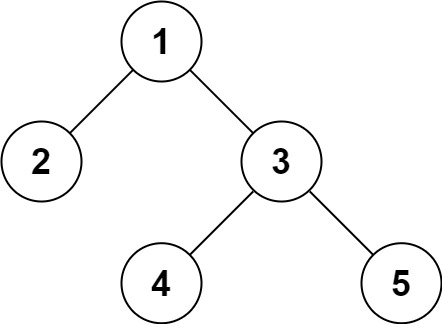
输入:root = [1,2,3,null,null,4,5] 输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:
输入:root = [1,2] 输出:[1,2]
提示:
- 树中结点数在范围
[0, 104]内 -1000 <= Node.val <= 1000
压缩字符串
给你一个字符数组 chars ,请使用下述算法压缩:
从一个空字符串 s 开始。对于 chars 中的每组 连续重复字符 :
- 如果这一组长度为
1,则将字符追加到s中。 - 否则,需要向
s追加字符,后跟这一组的长度。
压缩后得到的字符串 s 不应该直接返回 ,需要转储到字符数组 chars 中。需要注意的是,如果组长度为 10 或 10 以上,则在 chars 数组中会被拆分为多个字符。
请在 修改完输入数组后 ,返回该数组的新长度。
你必须设计并实现一个只使用常量额外空间的算法来解决此问题。
示例 1:
输入:chars = ["a","a","b","b","c","c","c"] 输出:返回 6 ,输入数组的前 6 个字符应该是:["a","2","b","2","c","3"] 解释:"aa" 被 "a2" 替代。"bb" 被 "b2" 替代。"ccc" 被 "c3" 替代。
示例 2:
输入:chars = ["a"] 输出:返回 1 ,输入数组的前 1 个字符应该是:["a"] 解释:唯一的组是“a”,它保持未压缩,因为它是一个字符。
示例 3:
输入:chars = ["a","b","b","b","b","b","b","b","b","b","b","b","b"] 输出:返回 4 ,输入数组的前 4 个字符应该是:["a","b","1","2"]。 解释:由于字符 "a" 不重复,所以不会被压缩。"bbbbbbbbbbbb" 被 “b12” 替代。
提示:
1 <= chars.length <= 2000chars[i]可以是小写英文字母、大写英文字母、数字或符号
计数二进制子串
给定一个字符串 s,统计并返回具有相同数量 0 和 1 的非空(连续)子字符串的数量,并且这些子字符串中的所有 0 和所有 1 都是成组连续的。
重复出现(不同位置)的子串也要统计它们出现的次数。
示例 1:
输入:s = "00110011" 输出:6 解释:6 个子串满足具有相同数量的连续 1 和 0 :"0011"、"01"、"1100"、"10"、"0011" 和 "01" 。 注意,一些重复出现的子串(不同位置)要统计它们出现的次数。 另外,"00110011" 不是有效的子串,因为所有的 0(还有 1 )没有组合在一起。
示例 2:
输入:s = "10101" 输出:4 解释:有 4 个子串:"10"、"01"、"10"、"01" ,具有相同数量的连续 1 和 0 。
提示:
1 <= s.length <= 105s[i]为'0'或'1'