冗余连接
难度:
标签:
题目描述
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:

输入: edges = [[1,2], [1,3], [2,3]] 输出: [2,3]
示例 2:

输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]] 输出: [1,4]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的
代码结果
运行时间: 22 ms, 内存: 16.3 MB
/*
* 题目思路:
* 通过 Java Stream 实现类似功能。
* 由于 Java Stream 不直接支持并查集的实现,
* 我们还是需要手动维护并查集结构,但可以使用 Stream 来简化部分逻辑。
*/
import java.util.Arrays;
public class Solution {
public int[] findRedundantConnection(int[][] edges) {
int n = edges.length;
int[] parent = new int[n + 1];
Arrays.setAll(parent, i -> i); // 初始化并查集
return Arrays.stream(edges).filter(edge -> {
int u = edge[0], v = edge[1];
int pu = find(parent, u);
int pv = find(parent, v);
if (pu != pv) {
parent[pu] = pv;
return false;
}
return true;
}).findFirst().orElse(new int[0]); // 返回第一个检测到的附加边
}
private int find(int[] parent, int x) {
if (parent[x] != x) {
parent[x] = find(parent, parent[x]);
}
return parent[x];
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
冗余连接 II
在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。
返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
示例 1:
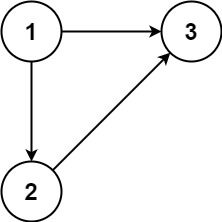
输入:edges = [[1,2],[1,3],[2,3]] 输出:[2,3]
示例 2:
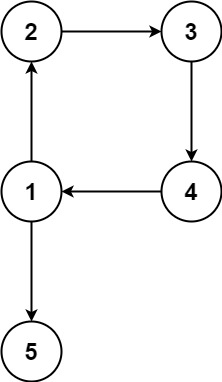
输入:edges = [[1,2],[2,3],[3,4],[4,1],[1,5]] 输出:[4,1]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ui, vi <= n
账户合并
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例 1:
输入:accounts = [["John", "[email protected]", "[email protected]"], ["John", "[email protected]"], ["John", "[email protected]", "[email protected]"], ["Mary", "[email protected]"]] 输出:[["John", '[email protected]', '[email protected]', '[email protected]'], ["John", "[email protected]"], ["Mary", "[email protected]"]] 解释: 第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "[email protected]"。 第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。 可以以任何顺序返回这些列表,例如答案 [['Mary','[email protected]'],['John','[email protected]'], ['John','[email protected]','[email protected]','[email protected]']] 也是正确的。
示例 2:
输入:accounts = [["Gabe","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Ethan","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]] 输出:[["Ethan","[email protected]","[email protected]","[email protected]"],["Gabe","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]]
提示:
1 <= accounts.length <= 10002 <= accounts[i].length <= 101 <= accounts[i][j].length <= 30accounts[i][0]由英文字母组成accounts[i][j] (for j > 0)是有效的邮箱地址