从叶结点开始的最小字符串
难度:
标签:
题目描述
给定一颗根结点为 root 的二叉树,树中的每一个结点都有一个 [0, 25] 范围内的值,分别代表字母 'a' 到 'z'。
返回 按字典序最小 的字符串,该字符串从这棵树的一个叶结点开始,到根结点结束。
注:字符串中任何较短的前缀在 字典序上 都是 较小 的:
- 例如,在字典序上
"ab"比"aba"要小。叶结点是指没有子结点的结点。
节点的叶节点是没有子节点的节点。
示例 1:

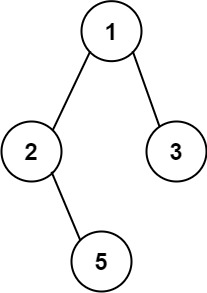
输入:root = [0,1,2,3,4,3,4] 输出:"dba"
示例 2:

输入:root = [25,1,3,1,3,0,2] 输出:"adz"
示例 3:

输入:root = [2,2,1,null,1,0,null,0] 输出:"abc"
提示:
- 给定树的结点数在
[1, 8500]范围内 0 <= Node.val <= 25
代码结果
运行时间: 26 ms, 内存: 17.3 MB
/*
* 思路:
* 1. 使用递归函数处理每个结点,将叶结点到根结点的字符串加入一个列表。
* 2. 使用Java Stream API对列表进行排序,并返回按字典序最小的字符串。
*/
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
class Solution {
public String smallestFromLeaf(TreeNode root) {
List<String> paths = new ArrayList<>();
buildPaths(root, new StringBuilder(), paths);
return paths.stream().sorted().findFirst().orElse("");
}
private void buildPaths(TreeNode node, StringBuilder sb, List<String> paths) {
if (node == null) return;
sb.append((char) ('a' + node.val));
if (node.left == null && node.right == null) {
sb.reverse();
paths.add(sb.toString());
sb.reverse();
}
buildPaths(node.left, sb, paths);
buildPaths(node.right, sb, paths);
sb.deleteCharAt(sb.length() - 1);
}
}
解释
方法:
这个题解采用了DFS(深度优先搜索)的方法来遍历整个二叉树。在遍历的过程中,使用一个列表 `path` 来存储从根节点到当前节点的路径。当到达一个叶节点(即没有子节点的节点)时,将 `path` 中的字符反转并连接成字符串,以得到从叶节点到根节点的字符串。然后,比较当前生成的字符串与先前找到的最小字符串,如果当前的更小,则更新结果字符串。这个过程持续进行,直到所有的叶节点都被访问过。最后,返回字典序最小的字符串。
时间复杂度:
O(n * h)
空间复杂度:
O(h) or O(n)
代码细节讲解
🦆
为什么在遍历到叶子节点时需要将路径中的字符进行反转?
▷🦆
在递归函数`__traverse`中,如果当前已找到的最小字符串`min_dict_order_str`非空,为何还需要继续比较当前字符串`curr_str`?
▷🦆
在存储路径的列表`path`中直接添加字符而不是节点的值有什么优势?
▷🦆
递归函数`__traverse`中的`if not root: return`是必要的吗,考虑到调用这个函数之前是否有检查节点是否存在?
▷相关问题
求根节点到叶节点数字之和
给你一个二叉树的根节点
root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:
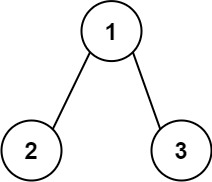
输入:root = [1,2,3] 输出:25 解释: 从根到叶子节点路径1->2代表数字12从根到叶子节点路径1->3代表数字13因此,数字总和 = 12 + 13 =25
示例 2:
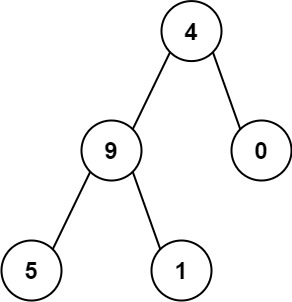
输入:root = [4,9,0,5,1] 输出:1026 解释: 从根到叶子节点路径4->9->5代表数字 495 从根到叶子节点路径4->9->1代表数字 491 从根到叶子节点路径4->0代表数字 40 因此,数字总和 = 495 + 491 + 40 =1026
提示:
- 树中节点的数目在范围
[1, 1000]内 0 <= Node.val <= 9- 树的深度不超过
10