账户合并
难度:
标签:
题目描述
代码结果
运行时间: 55 ms, 内存: 18.5 MB
/*
思路:
1. 使用Java Stream进行数据处理。
2. 主要逻辑和上面类似,但使用Stream API来简化代码。
3. 通过stream进行email到根节点的映射,然后使用stream收集最终结果。
*/
import java.util.*;
import java.util.stream.Collectors;
public class SolutionStream {
private Map<String, String> parent = new HashMap<>();
private Map<String, String> emailToName = new HashMap<>();
public List<List<String>> accountsMerge(List<List<String>> accounts) {
accounts.forEach(account -> {
String name = account.get(0);
account.stream().skip(1).forEach(email -> {
parent.putIfAbsent(email, email);
emailToName.putIfAbsent(email, name);
union(account.get(1), email);
});
});
Map<String, TreeSet<String>> unions = parent.keySet().stream().collect(Collectors.groupingBy(this::find, Collectors.toCollection(TreeSet::new)));
return unions.values().stream()
.map(emails -> {
List<String> account = new ArrayList<>(emails);
account.add(0, emailToName.get(account.get(0)));
return account;
})
.collect(Collectors.toList());
}
private String find(String email) {
return parent.get(email).equals(email) ? email : find(parent.get(email));
}
private void union(String email1, String email2) {
String root1 = find(email1);
String root2 = find(email2);
if (!root1.equals(root2)) {
parent.put(root1, root2);
}
}
}解释
方法:
这个题解使用了并查集的思路来解决账户合并问题。首先,为每个账户分配一个唯一的编号,然后遍历所有账户的邮箱地址,将具有相同邮箱地址的账户合并到一个集合中。最后,遍历并查集,将属于同一个集合的邮箱地址合并到一起,并按照字典序排序,与账户名一起作为结果返回。
时间复杂度:
O(nmlogm),其中 n 为账户数量,m 为每个账户邮箱地址数量的上限。
空间复杂度:
O(nm),其中 n 为账户数量,m 为每个账户邮箱地址数量的上限。
代码细节讲解
🦆
在账户合并的问题中,为什么选择使用并查集而不是其他数据结构如哈希表或图?
▷🦆
并查集在执行路径压缩时如何确保不会破坏已有的集合结构,特别是当存在多个邮箱共享时?
▷🦆
在构建emailToAcc映射时,如果两个不同的账户有相同的邮箱,如何处理这种冲突以保证正确的账户合并?
▷🦆
合并过程中,如何保证最终输出的账户名称是正确的,尤其是当多个账户因为共享邮箱而合并时?
▷相关问题
冗余连接
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:
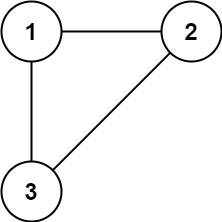
输入: edges = [[1,2], [1,3], [2,3]] 输出: [2,3]
示例 2:
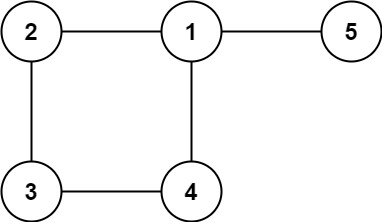
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]] 输出: [1,4]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的