句子相似性 II
难度:
标签:
题目描述
代码结果
运行时间: 62 ms, 内存: 19.2 MB
// Problem: Sentence Similarity II
// Given two sentences and a list of similar word pairs, determine if the two sentences are similar.
// Sentences are represented as arrays of strings, and similar word pairs are given as a 2D array.
// Two sentences are similar if the words in one sentence can be replaced with similar words to get the other sentence.
import java.util.*;
import java.util.stream.Collectors;
public class SentenceSimilarityIIStream {
private Map<String, String> parent;
public SentenceSimilarityIIStream() {
this.parent = new HashMap<>();
}
private String find(String word) {
parent.putIfAbsent(word, word);
if (!parent.get(word).equals(word)) {
parent.put(word, find(parent.get(word)));
}
return parent.get(word);
}
private void union(String word1, String word2) {
String root1 = find(word1);
String root2 = find(word2);
if (!root1.equals(root2)) {
parent.put(root1, root2);
}
}
public boolean areSentencesSimilarTwo(String[] sentence1, String[] sentence2, List<List<String>> similarPairs) {
if (sentence1.length != sentence2.length) {
return false;
}
similarPairs.forEach(pair -> union(pair.get(0), pair.get(1)));
return IntStream.range(0, sentence1.length)
.allMatch(i -> find(sentence1[i]).equals(find(sentence2[i])));
}
public static void main(String[] args) {
SentenceSimilarityIIStream similarityChecker = new SentenceSimilarityIIStream();
String[] sentence1 = {"great", "acting", "skills"};
String[] sentence2 = {"fine", "drama", "talent"};
List<List<String>> similarPairs = Arrays.asList(
Arrays.asList("great", "good"),
Arrays.asList("fine", "good"),
Arrays.asList("drama", "acting"),
Arrays.asList("skills", "talent")
);
System.out.println(similarityChecker.areSentencesSimilarTwo(sentence1, sentence2, similarPairs)); // true
}
}
解释
方法:
该题解使用了并查集的思想。首先,将相似单词对构建成一个无向图,然后对两个句子中的每个单词进行遍历,对于每个单词,如果它没有出现在并查集中,就对它进行深度优先搜索,将所有与它相连的单词都归属到同一个集合中,并给该集合分配一个编号。最后,对于两个句子中的每个单词,检查它们是否属于同一个集合,如果有任意一对单词不属于同一个集合,就返回 False,否则返回 True。
时间复杂度:
O(m + n)
空间复杂度:
O(m + n)
代码细节讲解
🦆
为什么选择使用并查集而不是其他数据结构如哈希表或树来解决句子相似性的问题?
▷🦆
在构建无向图时,相似单词对的处理为什么要使得每对单词双向连接,即a到b和b到a都要连接?
▷🦆
在DFS中,如果一个单词已经被访问过,为什么选择跳过它而不是重新探索其相似单词?这样做有哪些潜在的优势或风险?
▷🦆
在将单词归属到集合中时,为什么在单词a处理后立即增加集合编号k,而不是在一系列相连单词处理完后再增加?
▷相关问题
省份数量
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例 1:
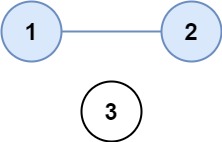
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2
示例 2:
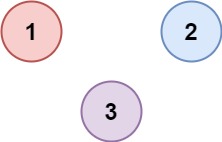
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] 输出:3
提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
账户合并
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例 1:
输入:accounts = [["John", "[email protected]", "[email protected]"], ["John", "[email protected]"], ["John", "[email protected]", "[email protected]"], ["Mary", "[email protected]"]] 输出:[["John", '[email protected]', '[email protected]', '[email protected]'], ["John", "[email protected]"], ["Mary", "[email protected]"]] 解释: 第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "[email protected]"。 第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。 可以以任何顺序返回这些列表,例如答案 [['Mary','[email protected]'],['John','[email protected]'], ['John','[email protected]','[email protected]','[email protected]']] 也是正确的。
示例 2:
输入:accounts = [["Gabe","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Ethan","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]] 输出:[["Ethan","[email protected]","[email protected]","[email protected]"],["Gabe","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]]
提示:
1 <= accounts.length <= 10002 <= accounts[i].length <= 101 <= accounts[i][j].length <= 30accounts[i][0]由英文字母组成accounts[i][j] (for j > 0)是有效的邮箱地址