二叉搜索树中第K小的元素
难度:
标签:
题目描述
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
示例 1:

输入:root = [3,1,4,null,2], k = 1 输出:1
示例 2:

输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3
提示:
- 树中的节点数为
n。 1 <= k <= n <= 1040 <= Node.val <= 104
进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?
代码结果
运行时间: 60 ms, 内存: 18.9 MB
/**
* 思路:
* 利用二叉搜索树的中序遍历的特性,用Java Stream API获取中序遍历的所有元素
* 然后直接获取第 k 个最小元素。
*/
import java.util.stream.Collectors;
import java.util.List;
public class Solution {
public int kthSmallest(TreeNode root, int k) {
List<Integer> sortedElements = inorder(root).stream().collect(Collectors.toList());
return sortedElements.get(k - 1);
}
private List<Integer> inorder(TreeNode root) {
if (root == null) return List.of();
List<Integer> left = inorder(root.left);
List<Integer> right = inorder(root.right);
return Stream.concat(Stream.concat(left.stream(), Stream.of(root.val)), right.stream()).collect(Collectors.toList());
}
}
解释
方法:
这个题解使用了迭代的方式进行中序遍历二叉搜索树。中序遍历二叉搜索树可以得到一个升序排列的序列,因此第k小的元素就是中序遍历序列中的第k个元素。具体做法是:用一个栈来模拟递归的过程,首先不断地将根节点的左子树压入栈中,直到左子树为空;然后弹出栈顶元素并将k减1,如果此时k等于0,说明已经找到了第k小的元素,直接返回该元素的值;否则继续遍历该元素的右子树。重复这个过程直到找到第k小的元素或遍历完整棵树。
时间复杂度:
O(h+k),其中h为树的高度
空间复杂度:
O(h),其中h为树的高度
代码细节讲解
🦆
在算法中,如何处理树中可能存在的相同值节点?这是否会影响第k小元素的查找?
▷🦆
为什么选择迭代方法而不是递归方法来进行中序遍历?两者在性能或内存使用上有何不同?
▷🦆
题解提到的进阶问题,如何优化算法以支持频繁的插入和删除操作?具体有哪些数据结构或技术可以用于优化?
▷🦆
在迭代过程中,如果k大于树的节点总数会发生什么?算法是否有处理这种边界情况的机制?
▷相关问题
二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3] 输出:[1,3,2]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
二叉树中第二小的节点
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0。如果一个节点有两个子节点的话,那么该节点的值等于两个子节点中较小的一个。
更正式地说,即 root.val = min(root.left.val, root.right.val) 总成立。
给出这样的一个二叉树,你需要输出所有节点中的 第二小的值 。
如果第二小的值不存在的话,输出 -1 。
示例 1:
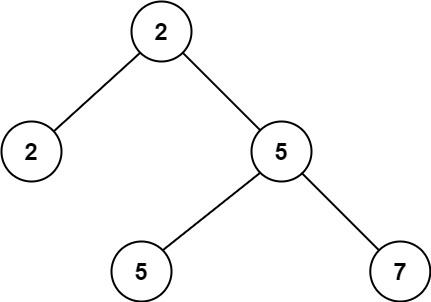
输入:root = [2,2,5,null,null,5,7] 输出:5 解释:最小的值是 2 ,第二小的值是 5 。
示例 2:
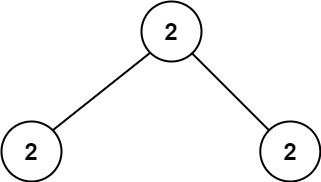
输入:root = [2,2,2] 输出:-1 解释:最小的值是 2, 但是不存在第二小的值。
提示:
- 树中节点数目在范围
[1, 25]内 1 <= Node.val <= 231 - 1- 对于树中每个节点
root.val == min(root.left.val, root.right.val)