收集所有金币可获得的最大积分
难度:
标签:
题目描述
There exists an undirected tree rooted at node 0 with n nodes labeled from 0 to n - 1. You are given a 2D integer array edges of length n - 1, where edges[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the tree. You are also given a 0-indexed array coins of size n where coins[i] indicates the number of coins in the vertex i, and an integer k.
Starting from the root, you have to collect all the coins such that the coins at a node can only be collected if the coins of its ancestors have been already collected.
Coins at nodei can be collected in one of the following ways:
- Collect all the coins, but you will get
coins[i] - kpoints. Ifcoins[i] - kis negative then you will loseabs(coins[i] - k)points. - Collect all the coins, but you will get
floor(coins[i] / 2)points. If this way is used, then for all thenodejpresent in the subtree ofnodei,coins[j]will get reduced tofloor(coins[j] / 2).
Return the maximum points you can get after collecting the coins from all the tree nodes.
Example 1:

Input: edges = [[0,1],[1,2],[2,3]], coins = [10,10,3,3], k = 5 Output: 11 Explanation: Collect all the coins from node 0 using the first way. Total points = 10 - 5 = 5. Collect all the coins from node 1 using the first way. Total points = 5 + (10 - 5) = 10. Collect all the coins from node 2 using the second way so coins left at node 3 will be floor(3 / 2) = 1. Total points = 10 + floor(3 / 2) = 11. Collect all the coins from node 3 using the second way. Total points = 11 + floor(1 / 2) = 11. It can be shown that the maximum points we can get after collecting coins from all the nodes is 11.
Example 2:
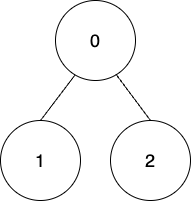
Input: edges = [[0,1],[0,2]], coins = [8,4,4], k = 0 Output: 16 Explanation: Coins will be collected from all the nodes using the first way. Therefore, total points = (8 - 0) + (4 - 0) + (4 - 0) = 16.
Constraints:
n == coins.length2 <= n <= 1050 <= coins[i] <= 104edges.length == n - 10 <= edges[i][0], edges[i][1] < n0 <= k <= 104
代码结果
运行时间: 613 ms, 内存: 64.3 MB
/*
题目思路:
1. 使用流操作构建树的结构。
2. 使用DFS从根节点开始遍历树。
3. 在每个节点,根据情况选择收集金币的方法。
4. 记录并返回最大积分。
*/
import java.util.*;
import java.util.stream.*;
class Solution {
private List<List<Integer>> tree;
private int[] coins;
private int k;
private int maxScore = 0;
public int collectCoins(int[][] edges, int[] coins, int k) {
int n = coins.length;
this.coins = coins;
this.k = k;
tree = IntStream.range(0, n).mapToObj(i -> new ArrayList<Integer>()).collect(Collectors.toList());
Arrays.stream(edges).forEach(edge -> {
tree.get(edge[0]).add(edge[1]);
tree.get(edge[1]).add(edge[0]);
});
boolean[] visited = new boolean[n];
dfs(0, visited);
return maxScore;
}
private void dfs(int node, boolean[] visited) {
visited[node] = true;
int childScore = 0;
for (int child : tree.get(node)) {
if (!visited[child]) {
dfs(child, visited);
childScore += coins[child];
}
}
int option1 = coins[node] - k;
int option2 = childScore / 2;
int score = Math.max(option1, option2);
maxScore += score;
coins[node] = score;
}
}
解释
方法:
时间复杂度:
空间复杂度: