另一棵树的子树
难度:
标签:
题目描述
Given the roots of two binary trees root and subRoot, return true if there is a subtree of root with the same structure and node values of subRoot and false otherwise.
A subtree of a binary tree tree is a tree that consists of a node in tree and all of this node's descendants. The tree tree could also be considered as a subtree of itself.
Example 1:
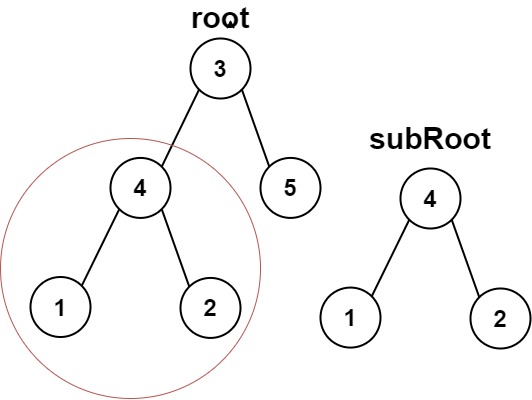
Input: root = [3,4,5,1,2], subRoot = [4,1,2] Output: true
Example 2:
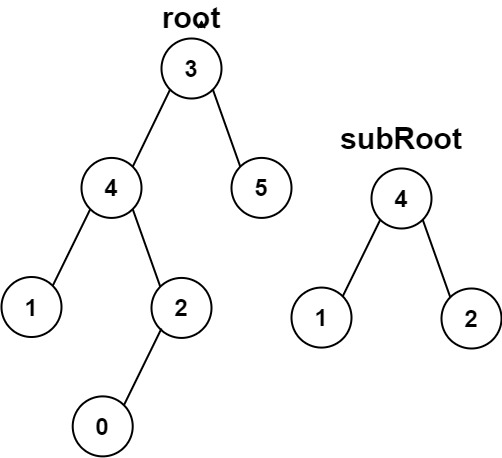
Input: root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2] Output: false
Constraints:
- The number of nodes in the
roottree is in the range[1, 2000]. - The number of nodes in the
subRoottree is in the range[1, 1000]. -104 <= root.val <= 104-104 <= subRoot.val <= 104
代码结果
运行时间: 42 ms, 内存: 16.3 MB
/*
题目思路:
1. 使用 Java Stream API 实现。
2. 我们定义一个方法 isSubtree 使用递归和流来判断 subRoot 是否是 root 的子树。
3. 在 root 的每个节点上,检查 isSameTree 函数是否为 true。
4. 如果 isSameTree 为真,返回 true;否则检查左子树和右子树。
*/
import java.util.stream.Stream;
public class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if (root == null) return subRoot == null;
return isSameTree(root, subRoot) || Stream.of(root.left, root.right).anyMatch(node -> isSubtree(node, subRoot));
}
private boolean isSameTree(TreeNode s, TreeNode t) {
if (s == null && t == null) return true;
if (s == null || t == null) return false;
if (s.val != t.val) return false;
return isSameTree(s.left, t.left) && isSameTree(s.right, t.right);
}
}解释
方法:
该题解使用了哈希的思想。首先通过 searchsub 函数计算出子树 subRoot 的哈希值,然后在主树 root 中通过 searchmain 函数查找是否存在一个子树的哈希值与 subRoot 的哈希值相等。如果存在,则说明主树中包含了与 subRoot 结构相同的子树,返回 True;否则返回 False。在计算哈希值时,使用了节点的值、左子树的哈希值和右子树的哈希值,并通过质数相乘的方式组合,以尽量避免哈希冲突。
时间复杂度:
O(m + n)
空间复杂度:
O(n)
代码细节讲解
🦆
为什么选择使用哈希方法来解决这个问题?是因为它比其他方法例如递归比较更高效吗?
▷🦆
在哈希函数中,使用了特定的质数31和179以及1000079进行计算。这些质数的选择有什么特别的理由或考虑吗?
▷🦆
哈希冲突是如何被处理的?在哈希值相同的情况下,是否有额外的步骤来确认两棵子树确实是结构和节点值都相同?
▷