岛屿数量
难度:
标签:
题目描述
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1
示例 2:
输入:grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] 输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
代码结果
运行时间: 200 ms, 内存: 0.0 MB
/*
* 题目思路:
* 1. 使用Java Stream的特性处理二维网格中的每个元素。
* 2. 找到'1'(陆地)时,使用递归消除岛屿的所有'1'。
* 3. 计算总的岛屿数量。
*/
import java.util.stream.IntStream;
public class SolutionStream {
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0) {
return 0;
}
int[] count = {0};
IntStream.range(0, grid.length).forEach(i ->
IntStream.range(0, grid[0].length).forEach(j -> {
if (grid[i][j] == '1') {
count[0]++;
dfs(grid, i, j);
}
})
);
return count[0];
}
private void dfs(char[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') {
return;
}
grid[i][j] = '0';
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
}
}
解释
方法:
这个题解使用深度优先搜索(DFS)的方法来解决岛屿数量问题。首先遍历整个网格,当遇到一个值为 '1' 的网格时,就将岛屿数量加一,然后以该网格为起点进行 DFS 搜索。在 DFS 搜索中,首先将当前网格标记为 '#' 表示已访问过,然后递归地对上下左右四个方向进行搜索。通过 DFS 搜索,可以将一个岛屿的所有陆地网格都标记为已访问,这样就不会重复计数。最终岛屿的数量即为进行 DFS 搜索的次数。
时间复杂度:
O(m*n)
空间复杂度:
O(m*n)
代码细节讲解
🦆
在 DFS 搜索中,为什么选择将遇到的 '1' 修改为 '#' 而不是其他标记,这会对算法的正确性或效率有何影响?
▷🦆
递归深度可能达到 m*n 的最坏情况下,是否有可能造成栈溢出?如果有,如何优化以避免此问题?
▷🦆
如何处理网格四周边界的情况?题解中是否包含了对此的特别处理?
▷🦆
如果网格中间有大片的 '0' 区域,DFS 方法是否还是高效的?有没有更优的搜索策略?
▷相关问题
被围绕的区域
给你一个

m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例 1:
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] 输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] 解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的'O'都不会被填充为'X'。 任何不在边界上,或不与边界上的'O'相连的'O'最终都会被填充为'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
示例 2:
输入:board = [["X"]] 输出:[["X"]]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j]为'X'或'O'
岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:
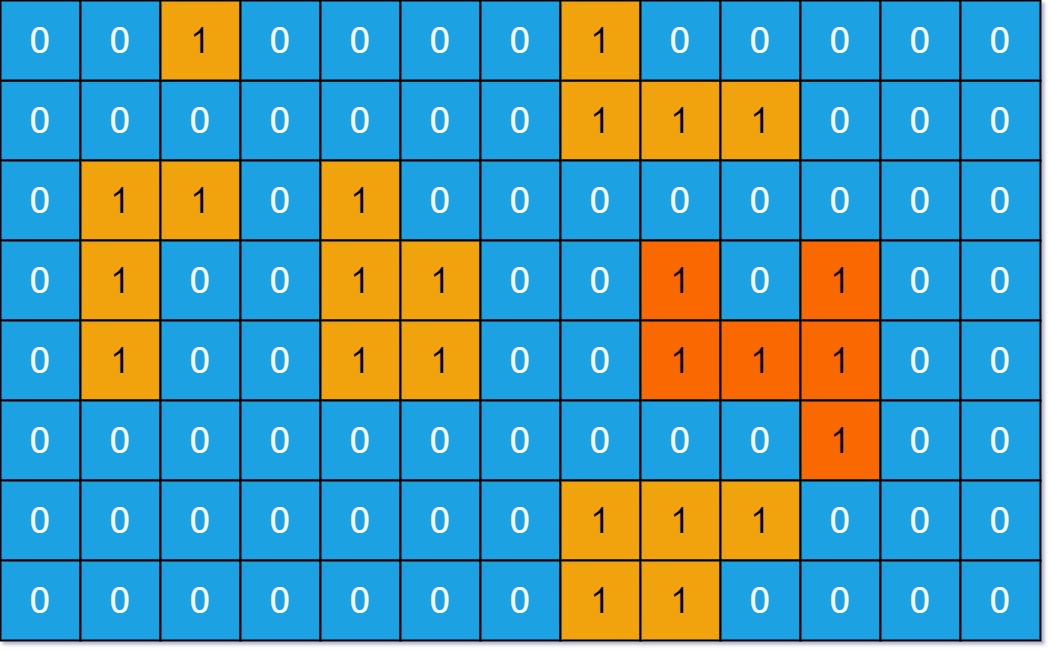
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 解释:答案不应该是11,因为岛屿只能包含水平或垂直这四个方向上的1。
示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]] 输出:0
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 50grid[i][j]为0或1