概率最大的路径
难度:
标签:
题目描述
You are given an undirected weighted graph of n nodes (0-indexed), represented by an edge list where edges[i] = [a, b] is an undirected edge connecting the nodes a and b with a probability of success of traversing that edge succProb[i].
Given two nodes start and end, find the path with the maximum probability of success to go from start to end and return its success probability.
If there is no path from start to end, return 0. Your answer will be accepted if it differs from the correct answer by at most 1e-5.
Example 1:
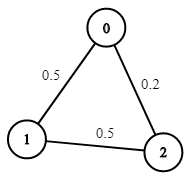
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2 Output: 0.25000 Explanation: There are two paths from start to end, one having a probability of success = 0.2 and the other has 0.5 * 0.5 = 0.25.
Example 2:
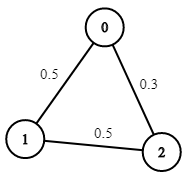
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2 Output: 0.30000
Example 3:
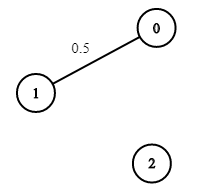
Input: n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2 Output: 0.00000 Explanation: There is no path between 0 and 2.
Constraints:
2 <= n <= 10^40 <= start, end < nstart != end0 <= a, b < na != b0 <= succProb.length == edges.length <= 2*10^40 <= succProb[i] <= 1- There is at most one edge between every two nodes.
代码结果
运行时间: 121 ms, 内存: 26.2 MB
/*
* 思路:使用Dijkstra算法变种,将成功概率最大的路径视为距离最短路径。
* 使用优先队列来维护当前最大概率的节点,并不断更新其邻接点的概率值。
* 使用Java Stream API进行流式处理。
*/
import java.util.*;
import java.util.stream.*;
public class SolutionStream {
public double maxProbability(int n, int[][] edges, double[] succProb, int start, int end) {
Map<Integer, List<Node>> graph = IntStream.range(0, n)
.boxed()
.collect(Collectors.toMap(i -> i, i -> new ArrayList<>()));
IntStream.range(0, edges.length).forEach(i -> {
graph.get(edges[i][0]).add(new Node(edges[i][1], succProb[i]));
graph.get(edges[i][1]).add(new Node(edges[i][0], succProb[i]));
});
double[] prob = new double[n];
prob[start] = 1.0;
PriorityQueue<Node> pq = new PriorityQueue<>((a, b) -> Double.compare(b.prob, a.prob));
pq.offer(new Node(start, 1.0));
while (!pq.isEmpty()) {
Node current = pq.poll();
int curNode = current.node;
double curProb = current.prob;
if (curNode == end) {
return curProb;
}
graph.get(curNode).stream()
.forEach(neighbor -> {
double newProb = curProb * neighbor.prob;
if (newProb > prob[neighbor.node]) {
prob[neighbor.node] = newProb;
pq.offer(new Node(neighbor.node, newProb));
}
});
}
return 0.0;
}
class Node {
int node;
double prob;
Node(int node, double prob) {
this.node = node;
this.prob = prob;
}
}
}
解释
方法:
这道题使用了图的最短路径算法的变种来寻找最大成功概率的路径。它使用了优先队列(堆)来实现一个类似于Dijkstra算法的过程,但是由于我们寻找的是最大概率而不是最短距离,我们在堆中存储的是概率的负值,以便最大概率的路径可以优先被处理。算法首先建立了一个图的邻接表表示,然后使用优先队列迭代地选择当前最大概率路径直到到达终点或队列为空,最后如果到达终点则返回当前的概率,否则返回0。
时间复杂度:
O(E log E)
空间复杂度:
O(N + E)
代码细节讲解
🦆
为什么在实现算法时选择使用优先队列(堆)而不是其他数据结构如队列或栈?
▷🦆
在优先队列中使用概率的负值是基于什么考虑?这种表示方式有哪些优势?
▷🦆
算法中如何处理图中存在的多条边连接同一对节点的情况?是否考虑了概率的合并或选择?
▷