分隔链表
难度:
标签:
题目描述
给你一个头结点为 head 的单链表和一个整数 k ,请你设计一个算法将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等:任意两部分的长度差距不能超过 1 。这可能会导致有些部分为 null 。
这 k 个部分应该按照在链表中出现的顺序排列,并且排在前面的部分的长度应该大于或等于排在后面的长度。
返回一个由上述 k 部分组成的数组。
示例 1:

输入:head = [1,2,3], k = 5 输出:[[1],[2],[3],[],[]] 解释: 第一个元素 output[0] 为 output[0].val = 1 ,output[0].next = null 。 最后一个元素 output[4] 为 null ,但它作为 ListNode 的字符串表示是 [] 。
示例 2:

输入:head = [1,2,3,4,5,6,7,8,9,10], k = 3 输出:[[1,2,3,4],[5,6,7],[8,9,10]] 解释: 输入被分成了几个连续的部分,并且每部分的长度相差不超过 1 。前面部分的长度大于等于后面部分的长度。
提示:
- 链表中节点的数目在范围
[0, 1000] 0 <= Node.val <= 10001 <= k <= 50
代码结果
运行时间: 52 ms, 内存: 15.4 MB
/*
* 思路:
* 1. 将链表节点收集到一个列表中。
* 2. 计算每部分的基本长度,以及需要加一个节点的部分数量。
* 3. 使用Stream API将列表分割成若干部分。
*/
import java.util.*;
import java.util.stream.*;
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class Solution {
public ListNode[] splitListToParts(ListNode root, int k) {
List<ListNode> nodes = new ArrayList<>();
while (root != null) {
nodes.add(root);
root = root.next;
}
int length = nodes.size();
int baseSize = length / k;
int extraNodes = length % k;
List<ListNode[]> parts = IntStream.range(0, k).mapToObj(i -> {
int size = baseSize + (i < extraNodes ? 1 : 0);
ListNode[] part = new ListNode[size];
for (int j = 0; j < size; j++) {
part[j] = nodes.isEmpty() ? null : nodes.remove(0);
if (j > 0 && part[j] != null) part[j-1].next = part[j];
}
if (part.length > 0 && part[part.length - 1] != null) part[part.length - 1].next = null;
return part;
}).toArray(ListNode[][]::new);
return Arrays.stream(parts).map(part -> part[0]).toArray(ListNode[]::new);
}
}解释
方法:
此题解的思路是先计算链表的总长度,然后根据总长度和要分隔的部分数k,计算每部分的长度。具体来说:
1. 用总长度整除k得到每部分的基本长度a
2. 用总长度对k取余得到多出来的节点数b
3. 将多出的b个节点平均分配到前b个部分,使得前b个部分的长度都是a+1
4. 从头节点开始,根据每部分的长度切割链表,得到k个部分
5. 将切割后的k个部分存入结果数组中返回
时间复杂度:
O(n+k)
空间复杂度:
O(k)
代码细节讲解
🦆
在计算每部分长度时,为何选择将额外的节点数b平均分配到前b个部分,这样的设计有什么特定的优势吗?
▷🦆
如果链表的总长度小于k,在返回结果中包含多个null的部分,这是否意味着在算法中还需要特别处理长度为0的情况?
▷🦆
函数`cut`在处理切割链表时,如果n等于1,那么p在移动n-1步后是否会直接指向null,这种情况下如何正确处理链表的切割?
▷🦆
算法在切割链表时对于每个部分使用了循环来找到切割点,这是否意味着每次切割都需要从头开始遍历到当前切割点?如果是,这对性能有何影响?
▷相关问题
旋转链表
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
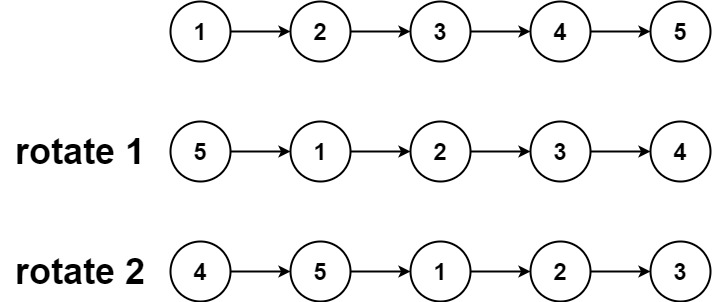
输入:head = [1,2,3,4,5], k = 2 输出:[4,5,1,2,3]
示例 2:
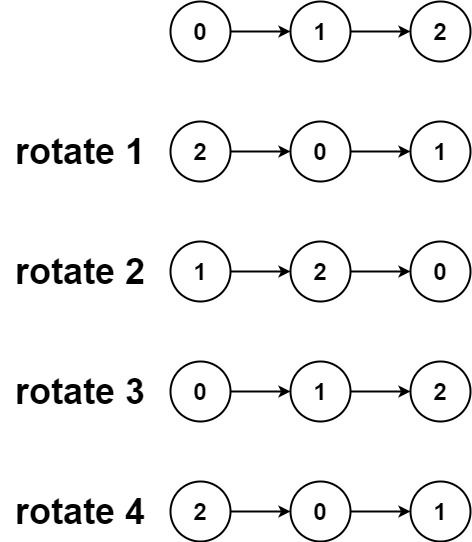
输入:head = [0,1,2], k = 4 输出:[2,0,1]
提示:
- 链表中节点的数目在范围
[0, 500]内 -100 <= Node.val <= 1000 <= k <= 2 * 109
奇偶链表
给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。
第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。
示例 1:
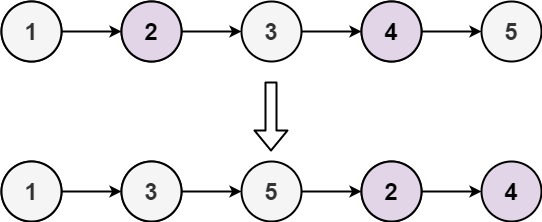
输入: head = [1,2,3,4,5] 输出: [1,3,5,2,4]
示例 2:
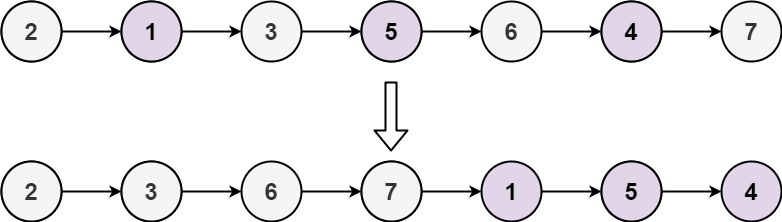
输入: head = [2,1,3,5,6,4,7] 输出: [2,3,6,7,1,5,4]
提示:
n ==链表中的节点数0 <= n <= 104-106 <= Node.val <= 106