根据描述创建二叉树
难度:
标签:
题目描述
You are given a 2D integer array descriptions where descriptions[i] = [parenti, childi, isLefti] indicates that parenti is the parent of childi in a binary tree of unique values. Furthermore,
- If
isLefti == 1, thenchildiis the left child ofparenti. - If
isLefti == 0, thenchildiis the right child ofparenti.
Construct the binary tree described by descriptions and return its root.
The test cases will be generated such that the binary tree is valid.
Example 1:
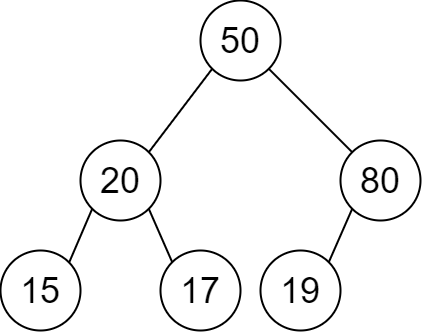
Input: descriptions = [[20,15,1],[20,17,0],[50,20,1],[50,80,0],[80,19,1]] Output: [50,20,80,15,17,19] Explanation: The root node is the node with value 50 since it has no parent. The resulting binary tree is shown in the diagram.
Example 2:
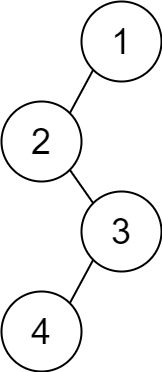
Input: descriptions = [[1,2,1],[2,3,0],[3,4,1]] Output: [1,2,null,null,3,4] Explanation: The root node is the node with value 1 since it has no parent. The resulting binary tree is shown in the diagram.
Constraints:
1 <= descriptions.length <= 104descriptions[i].length == 31 <= parenti, childi <= 1050 <= isLefti <= 1- The binary tree described by
descriptionsis valid.
代码结果
运行时间: 325 ms, 内存: 23.8 MB
/*
* 题目思路:
* 1. 使用一个HashMap来存储所有节点值对应的TreeNode。
* 2. 使用一个HashSet来记录所有有父节点的节点,这样可以通过遍历来确定根节点(即没有父节点的节点)。
* 3. 使用Java Stream API来遍历descriptions数组,为每个节点创建TreeNode对象,更新父子关系。
* 4. 最后从HashMap中获取根节点并返回。
*/
import java.util.*;
import java.util.stream.Collectors;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int val) { this.val = val; }
}
public class Solution {
public TreeNode createBinaryTree(int[][] descriptions) {
Map<Integer, TreeNode> map = new HashMap<>();
Set<Integer> children = new HashSet<>();
Arrays.stream(descriptions).forEach(desc -> {
int parent = desc[0], child = desc[1], isLeft = desc[2];
TreeNode parentNode = map.computeIfAbsent(parent, k -> new TreeNode(parent));
TreeNode childNode = map.computeIfAbsent(child, k -> new TreeNode(child));
if (isLeft == 1) {
parentNode.left = childNode;
} else {
parentNode.right = childNode;
}
children.add(child);
});
return map.entrySet().stream()
.filter(entry -> !children.contains(entry.getKey()))
.map(Map.Entry::getValue)
.findFirst()
.orElse(null); // 应该不会执行到这里,因为保证了有效的二叉树
}
}解释
方法:
此题解首先通过遍历给定的描述数组来构造二叉树。针对每个描述项 [parenti, childi, isLefti],如果 parenti 和 childi 在之前未曾创建,则创建相应的 TreeNode 对象,并存储在一个字典中,以节点的值作为键。另外,还用一个字典来标记每个节点是否可能是根节点,即如果一个节点作为 child 出现过,那么它就不可能是根节点。最后,遍历这个可能的根节点的字典,找到唯一的标记为 True 的节点,即为根节点。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
在构建二叉树的过程中,如果某个节点多次被标记为左或右子节点会如何处理?
▷🦆
如何确保最终只有一个节点被标记为根节点?如果出现多个节点未被作为子节点引用,应如何处理?
▷🦆
为什么在处理每个节点对时,都要判断节点是否已经在字典中存在?这一步骤对算法的效率有什么影响?
▷🦆
题解中提到的查找根节点的方法是否最优?存在更高效的寻找根节点的方法吗?
▷