前K个高频单词
难度:
标签:
题目描述
代码结果
运行时间: 24 ms, 内存: 16.1 MB
/*
思路:
1. 使用流API处理数组。
2. 首先统计每个单词的频率。
3. 然后按频率降序排列,如果频率相同则按字典序升序排列。
4. 最后返回前k个元素。
*/
import java.util.*;
import java.util.stream.*;
public class TopKFrequentWordsStream {
public List<String> topKFrequent(String[] words, int k) {
Map<String, Long> count = Arrays.stream(words)
.collect(Collectors.groupingBy(w -> w, Collectors.counting()));
return count.entrySet().stream()
.sorted((a, b) -> {
if (a.getValue().equals(b.getValue())) {
return a.getKey().compareTo(b.getKey());
}
return b.getValue().compareTo(a.getValue());
})
.limit(k)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
}
解释
方法:
此题解采用哈希表和最小堆(优先队列)的结合来解决问题。首先,使用一个哈希表(defaultdict)统计每个单词的出现次数。然后,定义一个自定义对象Word,它包含单词出现的次数和单词本身,重载其比较运算符以实现优先队列的正确功能。在遍历哈希表时,将每个单词以Word对象的形式添加到一个最小堆中。如果堆的大小超过k,则移除堆顶元素(出现次数最少的元素),以保持堆的大小为k。最后,从堆中取出所有元素,这些元素是按出现频率最小到最大排序的,所以需要反转以得到正确的顺序。
时间复杂度:
O(n log k)
空间复杂度:
O(n)
代码细节讲解
🦆
为什么在这个问题中选择使用最小堆来维护前k个高频单词,而不是使用最大堆或其他数据结构?
▷🦆
自定义对象Word重载了比较运算符,具体是如何确保在频率相同的情况下按字典顺序排列的?能否详细解释这一比较逻辑的实现?
▷🦆
解题思路提到最后需要将堆中的元素反转以得到正确的顺序,这是基于什么样的考虑?为什么不在插入时就维持正确的顺序?
▷相关问题
前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2]
示例 2:
输入: nums = [1], k = 1 输出: [1]
提示:
1 <= nums.length <= 105k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
最接近原点的 K 个点
给定一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点,并且是一个整数 k ,返回离原点 (0,0) 最近的 k 个点。
这里,平面上两点之间的距离是 欧几里德距离( √(x1 - x2)2 + (y1 - y2)2 )。
你可以按 任何顺序 返回答案。除了点坐标的顺序之外,答案 确保 是 唯一 的。
示例 1:
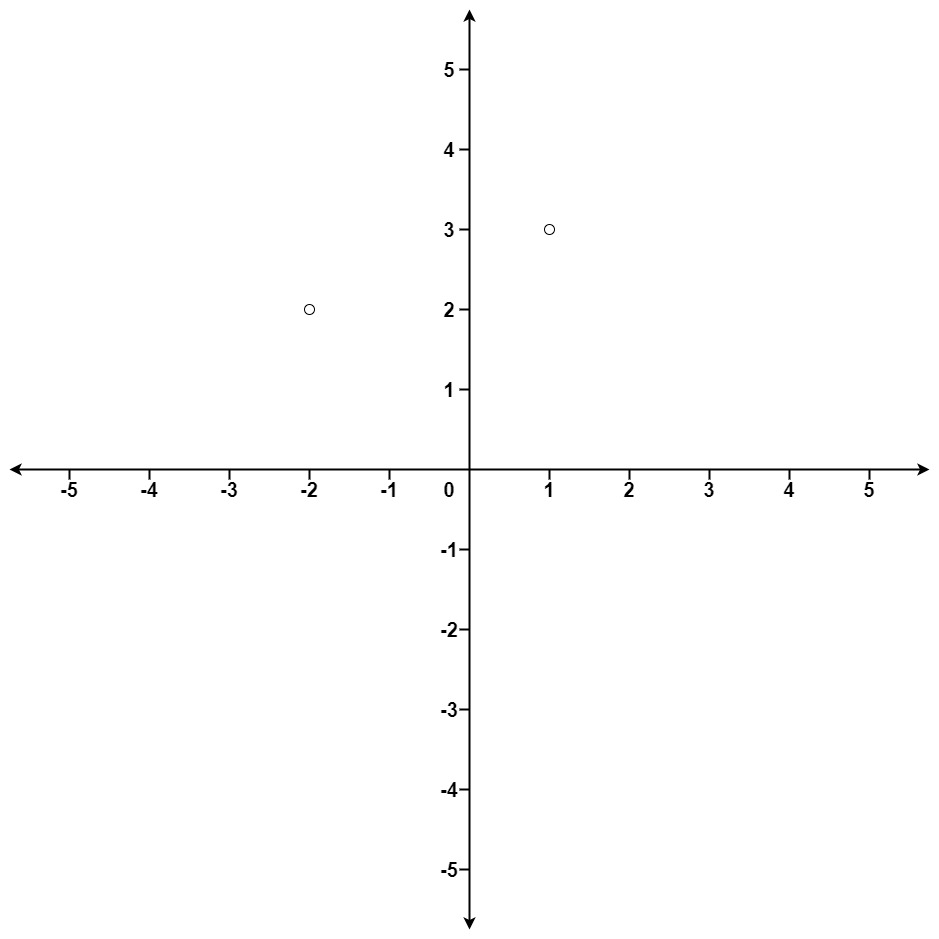
输入:points = [[1,3],[-2,2]], k = 1 输出:[[-2,2]] 解释: (1, 3) 和原点之间的距离为 sqrt(10), (-2, 2) 和原点之间的距离为 sqrt(8), 由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。 我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
示例 2:
输入:points = [[3,3],[5,-1],[-2,4]], k = 2 输出:[[3,3],[-2,4]] (答案 [[-2,4],[3,3]] 也会被接受。)
提示:
1 <= k <= points.length <= 104-104 < xi, yi < 104