合并区间
难度:
标签:
题目描述
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]] 输出:[[1,6],[8,10],[15,18]] 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]] 输出:[[1,5]] 解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
代码结果
运行时间: 48 ms, 内存: 15.5 MB
/*
* Problem: Merge Intervals
* Approach using Java Stream:
* 1. Sort intervals by the start time using Stream API.
* 2. Use reduce method to merge overlapping intervals.
* 3. Collect the results to a list and convert to an array.
*/
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Solution {
public int[][] merge(int[][] intervals) {
if (intervals.length <= 1) return intervals;
List<int[]> merged = Arrays.stream(intervals)
.sorted((a, b) -> Integer.compare(a[0], b[0]))
.reduce(new ArrayList<>(), (acc, interval) -> {
if (acc.isEmpty() || acc.get(acc.size() - 1)[1] < interval[0]) {
acc.add(interval);
} else {
acc.get(acc.size() - 1)[1] = Math.max(acc.get(acc.size() - 1)[1], interval[1]);
}
return acc;
}, (a, b) -> a);
return merged.toArray(new int[merged.size()][]);
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
插入区间
给你一个 无重叠的 ,按照区间起始端点排序的区间列表 intervals,其中 intervals[i] = [starti, endi] 表示第 i 个区间的开始和结束,并且 intervals 按照 starti 升序排列。同样给定一个区间 newInterval = [start, end] 表示另一个区间的开始和结束。
在 intervals 中插入区间 newInterval,使得 intervals 依然按照 starti 升序排列,且区间之间不重叠(如果有必要的话,可以合并区间)。
返回插入之后的 intervals。
注意 你不需要原地修改 intervals。你可以创建一个新数组然后返回它。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5] 输出:[[1,5],[6,9]]
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8] 输出:[[1,2],[3,10],[12,16]] 解释:这是因为新的区间[4,8]与[3,5],[6,7],[8,10]重叠。
提示:
0 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 105intervals根据starti按 升序 排列newInterval.length == 20 <= start <= end <= 105
提莫攻击
在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。
当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。
正式地讲,提莫在 t 发起攻击意味着艾希在时间区间 [t, t + duration - 1](含 t 和 t + duration - 1)处于中毒状态。如果提莫在中毒影响结束 前 再次攻击,中毒状态计时器将会 重置 ,在新的攻击之后,中毒影响将会在 duration 秒后结束。
给你一个 非递减 的整数数组 timeSeries ,其中 timeSeries[i] 表示提莫在 timeSeries[i] 秒时对艾希发起攻击,以及一个表示中毒持续时间的整数 duration 。
返回艾希处于中毒状态的 总 秒数。
示例 1:
输入:timeSeries = [1,4], duration = 2 输出:4 解释:提莫攻击对艾希的影响如下: - 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。 - 第 4 秒,提莫再次攻击艾希,艾希中毒状态又持续 2 秒,即第 4 秒和第 5 秒。 艾希在第 1、2、4、5 秒处于中毒状态,所以总中毒秒数是 4 。
示例 2:
输入:timeSeries = [1,2], duration = 2 输出:3 解释:提莫攻击对艾希的影响如下: - 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。 - 第 2 秒,提莫再次攻击艾希,并重置中毒计时器,艾希中毒状态需要持续 2 秒,即第 2 秒和第 3 秒。 艾希在第 1、2、3 秒处于中毒状态,所以总中毒秒数是 3 。
提示:
1 <= timeSeries.length <= 1040 <= timeSeries[i], duration <= 107timeSeries按 非递减 顺序排列
Range 模块
Range模块是跟踪数字范围的模块。设计一个数据结构来跟踪表示为 半开区间 的范围并查询它们。
半开区间 [left, right) 表示所有 left <= x < right 的实数 x 。
实现 RangeModule 类:
RangeModule()初始化数据结构的对象。void addRange(int left, int right)添加 半开区间[left, right),跟踪该区间中的每个实数。添加与当前跟踪的数字部分重叠的区间时,应当添加在区间[left, right)中尚未跟踪的任何数字到该区间中。boolean queryRange(int left, int right)只有在当前正在跟踪区间[left, right)中的每一个实数时,才返回true,否则返回false。void removeRange(int left, int right)停止跟踪 半开区间[left, right)中当前正在跟踪的每个实数。
示例 1:
输入 ["RangeModule", "addRange", "removeRange", "queryRange", "queryRange", "queryRange"] [[], [10, 20], [14, 16], [10, 14], [13, 15], [16, 17]] 输出 [null, null, null, true, false, true] 解释 RangeModule rangeModule = new RangeModule(); rangeModule.addRange(10, 20); rangeModule.removeRange(14, 16); rangeModule.queryRange(10, 14); 返回 true (区间 [10, 14) 中的每个数都正在被跟踪) rangeModule.queryRange(13, 15); 返回 false(未跟踪区间 [13, 15) 中像 14, 14.03, 14.17 这样的数字) rangeModule.queryRange(16, 17); 返回 true (尽管执行了删除操作,区间 [16, 17) 中的数字 16 仍然会被跟踪)
提示:
1 <= left < right <= 109- 在单个测试用例中,对
addRange、queryRange和removeRange的调用总数不超过104次
划分字母区间
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = "ababcbacadefegdehijhklij" 输出:[9,7,8] 解释: 划分结果为 "ababcbaca"、"defegde"、"hijhklij" 。 每个字母最多出现在一个片段中。 像 "ababcbacadefegde", "hijhklij" 这样的划分是错误的,因为划分的片段数较少。
示例 2:
输入:s = "eccbbbbdec" 输出:[10]
提示:
1 <= s.length <= 500s仅由小写英文字母组成
区间列表的交集
给定两个由一些 闭区间 组成的列表,firstList 和 secondList ,其中 firstList[i] = [starti, endi] 而 secondList[j] = [startj, endj] 。每个区间列表都是成对 不相交 的,并且 已经排序 。
返回这 两个区间列表的交集 。
形式上,闭区间 [a, b](其中 a <= b)表示实数 x 的集合,而 a <= x <= b 。
两个闭区间的 交集 是一组实数,要么为空集,要么为闭区间。例如,[1, 3] 和 [2, 4] 的交集为 [2, 3] 。
示例 1:
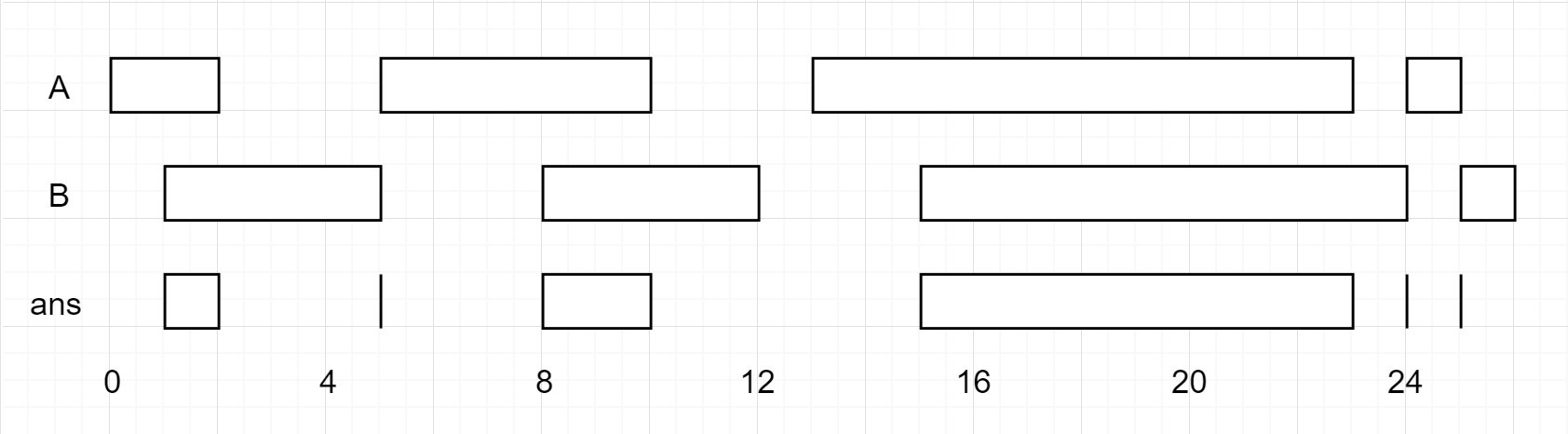
输入:firstList = [[0,2],[5,10],[13,23],[24,25]], secondList = [[1,5],[8,12],[15,24],[25,26]] 输出:[[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]]
示例 2:
输入:firstList = [[1,3],[5,9]], secondList = [] 输出:[]
示例 3:
输入:firstList = [], secondList = [[4,8],[10,12]] 输出:[]
示例 4:
输入:firstList = [[1,7]], secondList = [[3,10]] 输出:[[3,7]]
提示:
0 <= firstList.length, secondList.length <= 1000firstList.length + secondList.length >= 10 <= starti < endi <= 109endi < starti+10 <= startj < endj <= 109endj < startj+1