具有所有最深节点的最小子树
难度:
标签:
题目描述
Given the root of a binary tree, the depth of each node is the shortest distance to the root.
Return the smallest subtree such that it contains all the deepest nodes in the original tree.
A node is called the deepest if it has the largest depth possible among any node in the entire tree.
The subtree of a node is a tree consisting of that node, plus the set of all descendants of that node.
Example 1:
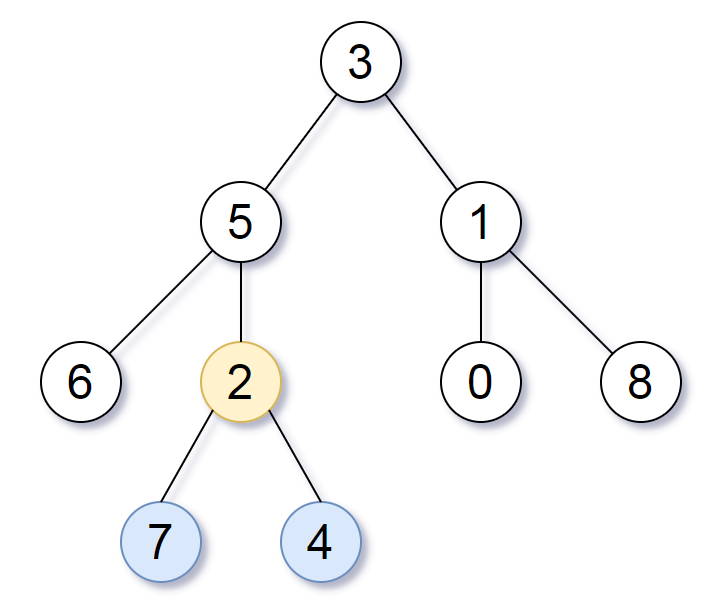
Input: root = [3,5,1,6,2,0,8,null,null,7,4] Output: [2,7,4] Explanation: We return the node with value 2, colored in yellow in the diagram. The nodes coloured in blue are the deepest nodes of the tree. Notice that nodes 5, 3 and 2 contain the deepest nodes in the tree but node 2 is the smallest subtree among them, so we return it.
Example 2:
Input: root = [1] Output: [1] Explanation: The root is the deepest node in the tree.
Example 3:
Input: root = [0,1,3,null,2] Output: [2] Explanation: The deepest node in the tree is 2, the valid subtrees are the subtrees of nodes 2, 1 and 0 but the subtree of node 2 is the smallest.
Constraints:
- The number of nodes in the tree will be in the range
[1, 500]. 0 <= Node.val <= 500- The values of the nodes in the tree are unique.
Note: This question is the same as 1123: https://leetcode.com/problems/lowest-common-ancestor-of-deepest-leaves/
代码结果
运行时间: 25 ms, 内存: 0.0 MB
/*
* 思路:
* 1. 使用深度优先搜索 (DFS) 计算每个节点的深度。
* 2. 使用 Java Stream 找出所有最深节点。
* 3. 找到这些最深节点的最近公共祖先 (LCA)。
* 4. 返回这个公共祖先节点。
*/
import java.util.*;
import java.util.stream.*;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
class Solution {
private Map<TreeNode, Integer> depthMap = new HashMap<>();
private int maxDepth = 0;
private TreeNode lca;
public TreeNode subtreeWithAllDeepest(TreeNode root) {
calculateDepth(root, 0);
List<TreeNode> deepestNodes = depthMap.entrySet().stream()
.filter(entry -> entry.getValue() == maxDepth)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
lca = findLCA(root, new HashSet<>(deepestNodes));
return lca;
}
private void calculateDepth(TreeNode node, int depth) {
if (node == null) return;
depthMap.put(node, depth);
maxDepth = Math.max(maxDepth, depth);
calculateDepth(node.left, depth + 1);
calculateDepth(node.right, depth + 1);
}
private TreeNode findLCA(TreeNode node, Set<TreeNode> deepestNodes) {
if (node == null || deepestNodes.contains(node)) return node;
TreeNode left = findLCA(node.left, deepestNodes);
TreeNode right = findLCA(node.right, deepestNodes);
if (left != null && right != null) return node;
return left != null ? left : right;
}
}解释
方法:
使用后序遍历的方式遍历二叉树。在遍历过程中,记录每个节点的高度,并比较左右子树的高度。如果左右子树高度相等,则当前节点就是最小子树的根节点;如果左子树高度大于右子树,则最小子树的根节点在左子树中;反之则在右子树中。最后返回最小子树的根节点。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
算法在处理只有一个节点的树(单节点树)时有何特殊考虑?是否还会执行比较左右子树高度的步骤?
▷🦆
在递归函数`traverse`中,如果左子树和右子树的高度不相等,为何选择高度较大的子树的根节点作为返回的节点?
▷🦆
算法中如何处理二叉树中的空节点?返回的高度为0是否有特殊的含义或者用途?
▷