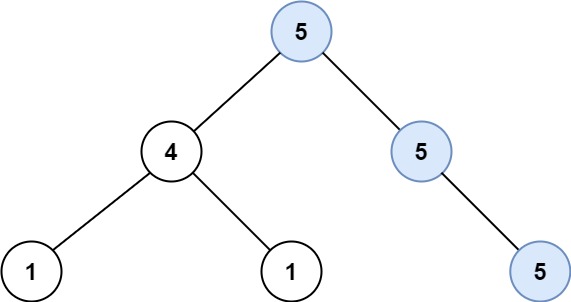
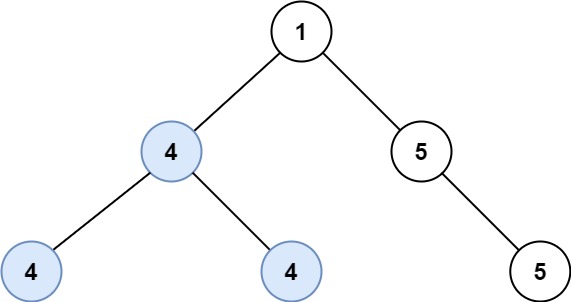
统计同值子树
难度:
标签:
题目描述
代码结果
运行时间: 26 ms, 内存: 16.2 MB
/*
思路:
1. 使用Java Stream API来处理二叉树节点的后序遍历。
2. 为每个节点判断其左右子树是否为同值子树,并且是否与当前节点值相同。
3. 如果满足条件,则增加计数器。
4. 最终返回计数器值。
*/
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Predicate;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public class Solution {
public int countUnivalSubtrees(TreeNode root) {
AtomicInteger count = new AtomicInteger(0);
Predicate<TreeNode> isUnivalSubtree = new Predicate<TreeNode>() {
@Override
public boolean test(TreeNode node) {
if (node == null) return true;
boolean left = test(node.left);
boolean right = test(node.right);
if (left && right) {
if (node.left != null && node.left.val != node.val) return false;
if (node.right != null && node.right.val != node.val) return false;
count.incrementAndGet();
return true;
}
return false;
}
};
isUnivalSubtree.test(root);
return count.get();
}
}解释
方法:
该题解采用递归的思路。对于每个节点,递归地判断其左右子树是否为同值子树。如果当前节点是叶子节点,则直接返回 True,并将计数器加 1。否则,分别递归判断左右子树。如果左右子树都是同值子树,且当前节点与左右子节点的值相同,则当前节点也是同值子树,将计数器加 1 并返回 True;否则返回 False。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
递归函数`isUnivalSubtree`在判断节点值是否相同时,如何处理当前节点与其左右子节点存在的空值情况?
▷🦆
在您的代码中,变量`isUnival`一旦被设置为`False`,是否会在后续递归中被重新设回`True`?这对结果有什么潜在影响?
▷🦆
在统计同值子树的数量时,您如何确保不会对某些子树进行重复计数?
▷相关问题
另一棵树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:
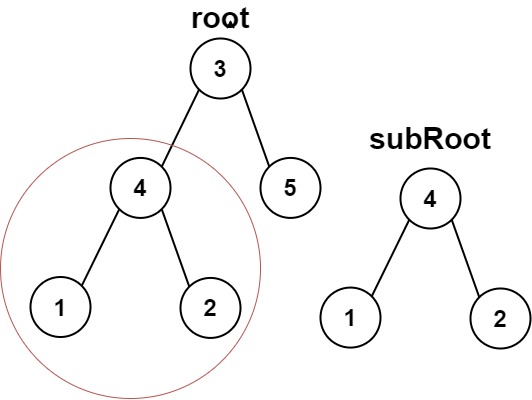
输入:root = [3,4,5,1,2], subRoot = [4,1,2] 输出:true
示例 2:
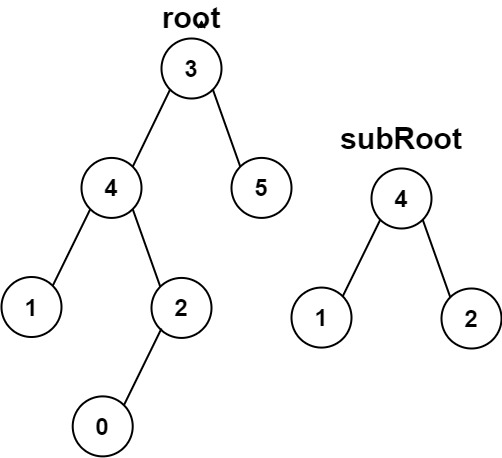
输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2] 输出:false
提示:
root树上的节点数量范围是[1, 2000]subRoot树上的节点数量范围是[1, 1000]-104 <= root.val <= 104-104 <= subRoot.val <= 104