数组中的第K个最大元素
难度:
标签:
题目描述
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
代码结果
运行时间: 61 ms, 内存: 27.1 MB
/*
* Problem: Given an integer array nums and an integer k, return the kth largest element in the array.
* You need to find the kth largest element in the sorted order, not the kth distinct element.
* You must implement a solution with O(n) time complexity.
*/
import java.util.Arrays;
public class Solution {
public int findKthLargest(int[] nums, int k) {
// Sort the array using Java Streams in descending order
return Arrays.stream(nums)
.boxed()
.sorted((a, b) -> b - a)
.limit(k)
.skip(k - 1)
.findFirst()
.get();
}
}解释
方法:
时间复杂度:
空间复杂度:
代码细节讲解
相关问题
摆动排序 II
给你一个整数数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]... 的顺序。
你可以假设所有输入数组都可以得到满足题目要求的结果。
示例 1:
输入:nums = [1,5,1,1,6,4] 输出:[1,6,1,5,1,4] 解释:[1,4,1,5,1,6] 同样是符合题目要求的结果,可以被判题程序接受。
示例 2:
输入:nums = [1,3,2,2,3,1] 输出:[2,3,1,3,1,2]
提示:
1 <= nums.length <= 5 * 1040 <= nums[i] <= 5000- 题目数据保证,对于给定的输入
nums,总能产生满足题目要求的结果
进阶:你能用 O(n) 时间复杂度和 / 或原地 O(1) 额外空间来实现吗?
前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2]
示例 2:
输入: nums = [1], k = 1 输出: [1]
提示:
1 <= nums.length <= 105k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
第三大的数
给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。
示例 1:
输入:[3, 2, 1] 输出:1 解释:第三大的数是 1 。
示例 2:
输入:[1, 2] 输出:2 解释:第三大的数不存在, 所以返回最大的数 2 。
示例 3:
输入:[2, 2, 3, 1] 输出:1 解释:注意,要求返回第三大的数,是指在所有不同数字中排第三大的数。 此例中存在两个值为 2 的数,它们都排第二。在所有不同数字中排第三大的数为 1 。
提示:
1 <= nums.length <= 104-231 <= nums[i] <= 231 - 1
进阶:你能设计一个时间复杂度 O(n) 的解决方案吗?
数据流中的第 K 大元素
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
KthLargest(int k, int[] nums)使用整数k和整数流nums初始化对象。int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素。
示例:
输入: ["KthLargest", "add", "add", "add", "add", "add"] [[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]] 输出: [null, 4, 5, 5, 8, 8] 解释: KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]); kthLargest.add(3); // return 4 kthLargest.add(5); // return 5 kthLargest.add(10); // return 5 kthLargest.add(9); // return 8 kthLargest.add(4); // return 8
提示:
1 <= k <= 1040 <= nums.length <= 104-104 <= nums[i] <= 104-104 <= val <= 104- 最多调用
add方法104次 - 题目数据保证,在查找第
k大元素时,数组中至少有k个元素
最接近原点的 K 个点
给定一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点,并且是一个整数 k ,返回离原点 (0,0) 最近的 k 个点。
这里,平面上两点之间的距离是 欧几里德距离( √(x1 - x2)2 + (y1 - y2)2 )。
你可以按 任何顺序 返回答案。除了点坐标的顺序之外,答案 确保 是 唯一 的。
示例 1:
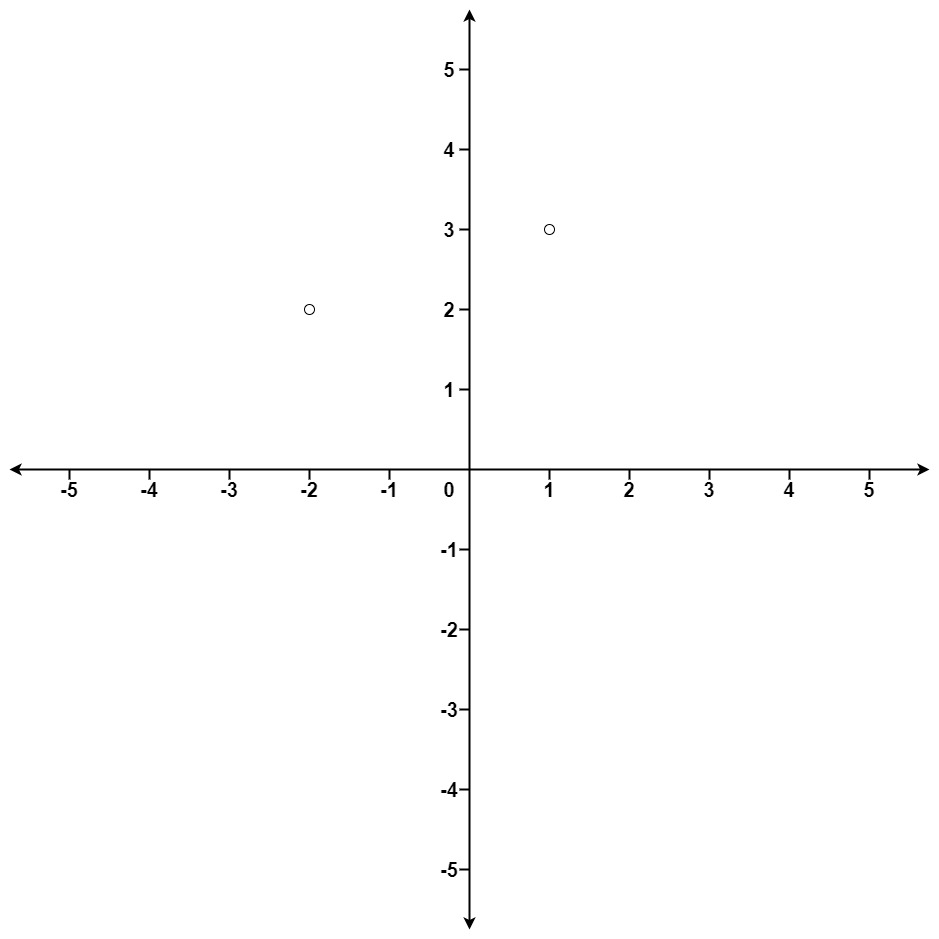
输入:points = [[1,3],[-2,2]], k = 1 输出:[[-2,2]] 解释: (1, 3) 和原点之间的距离为 sqrt(10), (-2, 2) 和原点之间的距离为 sqrt(8), 由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。 我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
示例 2:
输入:points = [[3,3],[5,-1],[-2,4]], k = 2 输出:[[3,3],[-2,4]] (答案 [[-2,4],[3,3]] 也会被接受。)
提示:
1 <= k <= points.length <= 104-104 < xi, yi < 104