序列化和反序列化 N 叉树
难度:
标签:
题目描述
代码结果
运行时间: 44 ms, 内存: 18.8 MB
/*
* 思路:
* 使用Java Stream API来实现序列化和反序列化。
* 我们将节点的值和子节点的数量序列化为字符串。
* 反序列化时,使用Stream生成节点。
*/
// 树节点定义
class Node {
public int val;
public List<Node> children;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, List<Node> _children) {
val = _val;
children = _children;
}
}
import java.util.stream.Collectors;
import java.util.stream.IntStream;
class Codec {
// 序列化
public String serialize(Node root) {
if (root == null) return "";
return serializeHelper(root).collect(Collectors.joining(" "));
}
// 辅助方法:前序遍历
private Stream<String> serializeHelper(Node node) {
if (node == null) return Stream.empty();
Stream<String> current = Stream.of(String.valueOf(node.val), String.valueOf(node.children.size()));
Stream<String> children = node.children.stream().flatMap(this::serializeHelper);
return Stream.concat(current, children);
}
// 反序列化
public Node deserialize(String data) {
if (data.isEmpty()) return null;
Iterator<String> it = Arrays.stream(data.split(" ")).iterator();
return deserializeHelper(it);
}
// 辅助方法:重建树
private Node deserializeHelper(Iterator<String> it) {
int val = Integer.parseInt(it.next());
int size = Integer.parseInt(it.next());
Node node = new Node(val, new ArrayList<>());
IntStream.range(0, size).forEach(i -> node.children.add(deserializeHelper(it)));
return node;
}
}解释
方法:
这个题解使用递归的方式对 N 叉树进行前序遍历,将树的结构编码为字符串进行序列化。在反序列化时,通过维护一个栈来存储当前节点的父节点,以便正确地重建树的结构。序列化时,每个节点的格式为 "值 [子节点...] ",其中方括号内是该节点的子节点序列。反序列化时,遇到数字则创建节点,遇到 "[" 则将当前节点压栈,遇到 "]" 则弹出栈顶节点。通过这种方式,可以正确地还原 N 叉树。
时间复杂度:
序列化:O(n^2),反序列化:O(n)
空间复杂度:
序列化:O(n+m),反序列化:O(n+m)
代码细节讲解
🦆
在序列化过程中,为什么选择使用前序遍历而不是其他遍历方法?这种选择对恢复树结构有什么特别的优势吗?
▷🦆
在序列化的格式中,使用空格和方括号来区分节点和子节点的开始与结束。这种格式在存在大量子节点或特别深的树时是否容易处理?是否有可能引入歧义或解析错误?
▷🦆
序列化时若节点值为数字外的其他类型(如字符串或混合类型),当前的序列化方法是否依然适用?需要做哪些调整?
▷🦆
在反序列化函数中,使用空字符串判断(if s == '')来跳过空格。这种方法是否最优?是否有更加高效的解析字符串的方法?
▷相关问题
二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
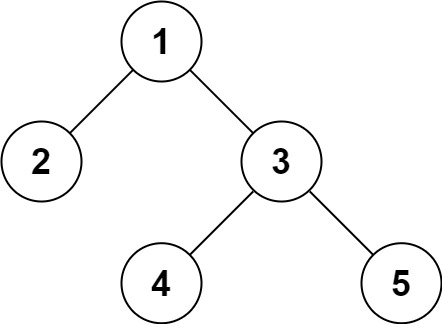
输入:root = [1,2,3,null,null,4,5] 输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:
输入:root = [1,2] 输出:[1,2]
提示:
- 树中结点数在范围
[0, 104]内 -1000 <= Node.val <= 1000
序列化和反序列化二叉搜索树
序列化是将数据结构或对象转换为一系列位的过程,以便它可以存储在文件或内存缓冲区中,或通过网络连接链路传输,以便稍后在同一个或另一个计算机环境中重建。
设计一个算法来序列化和反序列化 二叉搜索树 。 对序列化/反序列化算法的工作方式没有限制。 您只需确保二叉搜索树可以序列化为字符串,并且可以将该字符串反序列化为最初的二叉搜索树。
编码的字符串应尽可能紧凑。
示例 1:
输入:root = [2,1,3] 输出:[2,1,3]
示例 2:
输入:root = [] 输出:[]
提示:
- 树中节点数范围是
[0, 104] 0 <= Node.val <= 104- 题目数据 保证 输入的树是一棵二叉搜索树。