二叉树中第二小的节点
难度:
标签:
题目描述
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0。如果一个节点有两个子节点的话,那么该节点的值等于两个子节点中较小的一个。
更正式地说,即 root.val = min(root.left.val, root.right.val) 总成立。
给出这样的一个二叉树,你需要输出所有节点中的 第二小的值 。
如果第二小的值不存在的话,输出 -1 。
示例 1:

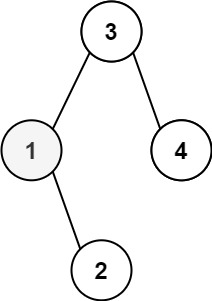
输入:root = [2,2,5,null,null,5,7] 输出:5 解释:最小的值是 2 ,第二小的值是 5 。
示例 2:

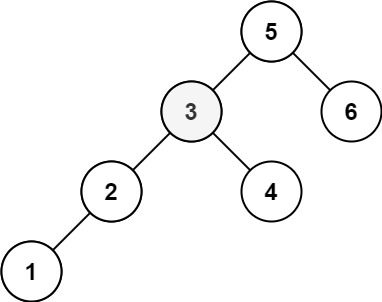
输入:root = [2,2,2] 输出:-1 解释:最小的值是 2, 但是不存在第二小的值。
提示:
- 树中节点数目在范围
[1, 25]内 1 <= Node.val <= 231 - 1- 对于树中每个节点
root.val == min(root.left.val, root.right.val)
代码结果
运行时间: 23 ms, 内存: 16.1 MB
/*
* 思路:
* 1. 使用广度优先搜索遍历整棵树,收集所有节点的值。
* 2. 使用 Stream 处理节点值的集合,首先找出最小值,然后过滤掉最小值,找出剩余值中的最小值。
* 3. 如果找不到第二小的值,返回 -1。
*/
import java.util.*;
import java.util.stream.*;
public class Solution {
public int secondMinimumValue(TreeNode root) {
Set<Integer> values = new HashSet<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
values.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
int min1 = values.stream().min(Integer::compare).orElse(Integer.MAX_VALUE);
int min2 = values.stream().filter(v -> v > min1).min(Integer::compare).orElse(-1);
return min2;
}
}解释
方法:
这个题解采用 BFS 的思路来遍历二叉树。首先初始化两个变量 a 和 b 来分别存储最小值和第二小的值,初始值均为无穷大。然后使用一个队列 q 来进行 BFS 遍历,每次从队列中取出一个节点,并将其左右子节点(如果存在)加入队列。在遍历过程中,不断更新 a 和 b 的值,如果当前节点的值小于等于 a,则更新 a;如果当前节点的值大于 a 且小于 b,则更新 b。最后,如果 a 或 b 的值仍为初始值(无穷大),说明不存在第二小的值,返回 -1,否则返回 b。
时间复杂度:
O(n)
空间复杂度:
O(n)
代码细节讲解
🦆
在题解中初始化了三个变量 a, b, 和 d 为无穷大,具体来说,这三个变量各自代表什么目的和作用?
▷🦆
题解中提到如果 a 或 b 的值仍为无穷大,则返回 -1。在什么情况下 a 和 b 的值会保持为无穷大,能否举例说明?
▷🦆
题解使用了 BFS 遍历,为什么选择 BFS 而不是 DFS,二者在这个问题上有什么具体的优势或劣势?
▷🦆
题解中更新 a 和 b 的条件是基于当前节点值的大小,这种更新方式是否能保证最终 b 确实是树中第二小的值?
▷